READING METHODS AND ONLINE LEXICAL ACCESS IN BEGGINER READERS
Delia Villar
Pilar Vieiro
Departamento de Psicología Evolutiva y de la Educación, Universidad de A Coruña. España
]]>
Resumen: El presente estudio fue diseñado con el objetivo de analizar el acceso al léxico on-line en alumnos de primero de primaria teniendo en cuenta el método de aprendizaje utilizado en la escuela. Con este fin seleccionamos dos grupos de alumnos (receptores de un método global y receptores de un método sintético-fonético) donde se analizaron las respuestas de los sujetos en base a las tasas de verificación (lectura de palabras) y tiempos de lectura. Para ello manipulamos los estímulos en base a una serie de criterios (grado de familiaridad de la palabra, longitud de la misma y frecuencia silábica posicional). Los estudiantes del método global mostraron mayores dificultades de decodificación ya que los tiempos de lectura en palabras de familiaridad baja y frecuencia silábica posicional baja fueron significativamente mayores. Mientras que los alumnos del método sintético resultaron ser más hábiles con la decodificación pero sus tiempos de lectura fueron significativamente mayores en prácticamente todos los parámetros. Por lo que se constata la idea de que el método de aprendizaje influye en las estrategias utilizadas por los estudiantes dependiendo de las características léxicas y subléxicas de la palabra.
Palabras Clave: acceso léxico; métodos de lectura; adquisición lectora
Abstract: The aim of this study was to analyze online lexical access in first-grade students according to the learning method used at school. To that end, we selected two groups of students depending on the learning method to read (global vs. synthetic - phonetic). We analyzed the responses of subjects based on verification rates (reading words) and time. We manipulated stimuli based on a set of criteria (degree of familiarity of the word, length and positional syllable frequency). Students who used overall method of decoding showed difficulties since their reading times in low familiarity words and low frequency positional syllabic were significantly higher. Students of the synthetic method proved more adept at decoding but their reading times were significantly higher in almost all parameters. These results confirm the idea that the method affects learning strategies used by students depending on the lexical and sublexical features of the word.
Key Words: lexical access; reading methods; reading acquisition
Correo Electrónico: vieiro@udc.es
Recibido: 04/2015
Revisado: 07/2015
Aceptado: 11/2015
La lectura es una herramienta fundamental para el desarrollo en una sociedad civilizada, por lo que su adquisición deficitaria provocará alumnos poco autónomos con los consiguientes efectos sobre el desarrollo cognitivo, afectivo y social (Stanovich, 2000), quizás por ello tanto padres como profesionales de la educación muestran un gran interés sobre cómo abordar la enseñanza de la lectura. En este contexto, el trabajo que aquí se presenta pretende analizar a través de tareas de lectura de palabras las vías de acceso al léxico que utilizan los sujetos que están comenzando el aprendizaje de la lectura con distinto método de enseñanza.
]]>
Marco Teórico
La lectura es una actividad cognitiva compleja a través de la cual convertimos los signos gráficos en significados; dicho proceso es relativamente complejo ya que supone la puesta en marcha de procesos perceptivos relacionados con el análisis visual (reconocemos las palabras como estímulos), el acceso al léxico (dando formato fonológico y grafémico a las mismas) y acceso al significado. Desde el punto de vista educativo, la lectura forma parte de los aprendizajes instrumentales y, por lo tanto, ha de ser enseñada con un método determinado (Hoien-Tengesdal & Hoien, 2012; Kewaza & Welch, 2013).
En su funcionamiento este proceso es complejo, tanto desde el punto de vista lingüístico como perceptivo y cognitivo debido a los múltiples procesos psico-lingüísticos básicos implicados en esta tarea. De todos ellos nos centraremos en el procesamiento léxico por ser objeto de estudio de la investigación que aquí presentamos.
El procesador léxico es el encargado de, una vez identificadas las unidades lingüísticas, encontrar el concepto con el que se asocia esa unidad. Para realizar este proceso disponemos de dos vías: una que conecta directamente los signos gráficos con el significado y otra que transforma los signos gráficos en sonidos y utiliza estos para llegar al significado, tal como ocurre en el lenguaje oral (Cuetos, 1990; Wang & Inhoff, 2013).
La ruta visual, léxica o directa es la responsable de comparar la forma ortográfica de la palabra con las representaciones almacenadas en la memoria para comprobar con cuál encaja, por esta ruta se leerían todas las palabras conocidas (Morton, 1980; Morton & Patterson, 1980; Patterson & Sewell, 1987). La ruta fonológica o indirecta permite identificar cada una de las letras que componen las palabras para su posterior transformación en sonidos. Por lo que en esta ruta el reconocimiento de las palabras sería a través de los sonidos, tal como sucede en el lenguaje oral. A través de ella se leerían todas las palabras desconocidas y pseudopalabras (Ashby & Martin, 2008; Gollan, Slattery, Goldenberg, Van Assche, Duyck, & Rayner, 2011)
Como hemos planteamos al comienzo de este trabajo la lectura ha de ser enseñada con un método concreto, a tal fin se han ido desarrollando distintos métodos, los más utilizados son los métodos sintéticos y los métodos analíticos o globales, sin olvidar la perspectiva constructivista de acceso a la lectura. En este trabajo nos centraremos en los dos primeros por ser los que tomaremos como referencia a la hora de seleccionar las tareas ya que partimos como marco teórico de los modelos duales que defienden la idea del doble uso de la ruta fonológica y visual (Goswami & Bryant, 1990; Sowden & Stevenson, 1994).
Los métodos sintéticos-fonéticos son métodos que dan prioridad al proceso de aprendizaje y no al resultado del mismo, en ellos el conocimiento alfabético se convierte en una habilidad básica del aprendizaje lector, partiendo de que la fluidez y automatización de este conocimiento contribuyen a la comprensión, ocupando el contexto un papel secundario; se sostiene por tanto que las unidades de aprendizaje deben ser las estructuras lingüísticas más simples (grafema, fonema, sílaba) para posteriormente pasar a fusionar éstas en unidades más amplias con significado (palabra, frase), de este modo, los procesos de decodificación adquieren gran relevancia en estos métodos.
]]> Los métodos analíticos o globales defienden que el aprendizaje de la lectura debe comenzar por unidades con significado y dependientes de la información contextual. Así en su enseñanza comienzan por la frase o palabra y terminan en las sílabas y letras. La enseñanza de la lectura no se centra en sus inicios en la decodificación grafema-fonema, sino en el estudio de unidades complejas con significado (frases, palabras) para que al final del proceso el niño sea capaz de conocer y distinguir los elementos más simples (sílabas y letras) en base a la descomposición de esas unidades significativas. En lo que no parece existir unanimidad es en el momento en el que se debe iniciar la decodificación. Aunque la versión más pura de los métodos globales parte del estudio de la frase para terminar con el análisis de los elementos sencillos, existen, al igual que en los métodos sintéticos, distintas formas de abordar el aprendizaje: léxicos.Según Venezky (1978) la diferencia básica entre los dos métodos de enseñanza radica en el momento en el que se enseñan las reglas de conversión grafema-fonema, ya que los métodos sintéticos lo hacen desde el principio y los métodos globales lo posponen a etapas superiores.
Pero como señala Galera (2009) lo fundamental es conocer el proceso de enseñanza-aprendizaje mediante el cual el niño conecta, capta e interactúa con el texto. De ahí que con este trabajo se pretenda conocer cómo el niño accede a la lectura, teniendo en cuenta el método de aprendizaje.
Estudio
Planteamiento general del problema
]]>
Los estudios que se han basado en el análisis de los errores tales como los de Vannorsdall, Maroof, Gordon y Schretlen (2012) señalan también que los niños instruidos por método global adquieren la competencia de reconocimiento sin la capacidad de decodificación. En cambio, cuando la instrucción enfatiza las correspondencias letra-sonido, se acelera la adquisición de correspondencias subléxicas.
Otros estudios demostraron una influencia del método de enseñanza en habilidades explícitas para la segmentación del habla, demostrando que estas habilidades se desarrollan con más rapidez en el contexto de una instrucción fónica (Alegría, Pignot, & Morais 1982; Perfetti, Beck & Bell, & Hughes 1987). Alegría et al. (1982) mostraron que los niños enseñados con el método global obtenían peores resultados que los niños enseñados con el método fónico cuando se les pedía que invirtieran los fonemas de una palabra monosílaba presentada oralmente, mientras que el resultado de los grupos era comparable cuando la tarea consistía en invertir sílabas. De ello se desprende que en las primeras etapas de aprendizaje los métodos de enseñanza sí parecen tener una influencia sobre el desarrollo de los procesos fonológicos.
Bajo este contexto, el interés y novedad de este estudio radica en el estudio on-line de lectura de palabras a través de tres variables intrasujeto (grado de familiaridad de la palabra, longitud de la misma y frecuencia silábica posicional) para ello no sólo evaluaremos la lectura correcta de las mismas si no también los tiempos de lectura empleados. El análisis de dichas variables ha sido estudiado en investigaciones previas (véase, Guzmán, 1997) utilizando tareas de decisión léxica, de nombrar y errores en lectura de palabras y pseudopalabras. Por el contrario, en nuestro trabajo nos interesa sólo conocer la tasa de verificación y los tiempos de lectura de palabras; es decir, no pretendemos verificar el método de doble ruta tan estudiado en investigaciones previas (Domínguez & Cuetos, 1992; Guzmán, 1997) con resultados tan claramente concluyentes; si no analizar cómo cada uno de los métodos puede influir no sólo en la correcta lectura de las palabras sino también en el tiempo de procesamiento en función de unas características intrínsecas de la palabra.
En este sentido esperamos que: a) los alumnos de un método sintético-fonético se beneficiarán del mismo en la lectura de palabras de baja frecuencia tanto en la eficacia de lectura (tareas de verificación) como en sus tiempos de lectura; b) los alumnos del método sintético-fonético se verán afectados por la frecuencia silábica posicional (FSP) y la longitud de la palabra tanto en las tareas de verificación como en los tiempos de lectura en el sentido de que serán menos eficaces y más lentos que sus iguales con aprendizaje por el método global.
Método
La muestra del estudio estuvo compuesta por 40 sujetos, dos grupos de 20 alumnos de 1º de Educación Primaria pertenecientes a dos centros educativos de la provincia de La Coruña.
El primer grupo, el cual tenía como método de enseñanza de la lectura el método global, lo formaba alumnado con una media de edad de 6 años y 5 meses (rango comprendido entre los 6 años 2 meses y los 6 años 8 meses).
El segundo grupo, perteneciente al método analítico-sintético de enseñanza de la lectura, era alumnado con una media de edad de 6 años 8 meses (rango comprendido entre los 6 años 3 meses y los 6 años 9 meses).
Ninguno de los alumnos había alcanzado la etapa ortográfica de la lectura, ni presentaba dificultades en el aprendizaje escolar según la información proporcionada por sus tutores y el Departamento de Orientación del Centro.
Se ha utilizado el consentimiento informado de los padres para la participación en el estudio.
Para la selección de los estímulos se ha partido de la muestra planteada por Guzmán (1997) y se seleccionaron las palabras en función de los siguientes criterios:
- Frecuencia Léxica (Familiaridad) Alta y Baja
- Longitud Larga y Corta
- Frecuencia Silábica Posicional Alta y Baja
El primero de ellos, Frecuencia Léxica, hace referencia a la frecuencia con la que los niños utilizan una determinada palabra.
La longitud de la palabra hace referencia al número de letras por las que está compuesta, considerando las palabras de 5 letras o menos como palabras cortas y el resto como palabras largas.
La Frecuencia Silábica Posicional (FSP) es el número de veces que una sílaba aparece en una posición particular en una palabra. Esta ha sido determinada en base al estudio estadístico de la ortografía castellana de Álvarez, Carreiras y de Vega (1992). Se consideraron palabras de alta FSP cuando superaban el valor 74. Las palabras eran de baja FSP cuando el valor era menor de 71.
]]> Una vez seleccionados cada uno de los estímulos se procedió a escoger las palabras que cumplieran con los siguientes requisitos:Familiaridad Alta – Corta – F S P Alta: boca, gato, mano, vaca, rana, silla, vela, señal, coche, seta
Familiaridad Alta – Corta – FSP Baja: dado, balón, bebé, tren, fuego, árbol, dedo, sol, mar y yoyur.
Familiaridad Alta – Larga – FSP Alta: dinero, vacaciones, espada, aceitunas, serpiente, cuerda, cuchillo, tesoro, cáscara y tijera.
Familiaridad Alta – Larga – FSP. Baja: bocadillos, parchís, biblioteca, nombre, balcón, gusano, tambor, muchas, ombligo, sierra.
Familiaridad Baja – Corta – FSP Baja: liso, taxi, ceja, nudo, bomba, pupa, perla, noria, arpa, sauce.
Familiaridad Baja – Larga – FSP Alta: bufanda, patinete, carretilla, calamares, calendario, amapola, capucha, agricultor, acuarela y bellota.
Familiaridad Baja – Larga – FSP Baja: cangrejo, lunares, manguera, bosque, brocha, babosa, lombriz, cactus, balanza, alfarero.
Formando así 8 grupos de 10 palabras cada uno (clasificación tomada de Guzmán, 1997).
]]>
Diseño
Se realizó un diseño intergrupo donde las variables fueron asignadas y controladas de la siguiente manera:
Las Variables intersujeto fueron el Método de lectura Sintético-Fonético vs. Analítico-Global.
Las Variables intrasujeto fueron las ocho condiciones experimentales derivadas de la combinación: Longitud de la palabra (corta vs. larga), Familiaridad subjetiva (baja vs. alta) y Frecuencia Silábica Posicional (baja vs. alta).
Se controlaron como variables extrañas contrabalanceando la presentación de las tareas y evitando el posible efecto de factores contextuales (las pruebas se realizaron a la misma hora y por un experimentador conocido, la profesora que fue entrenada en por las autoras del trabajo en el registro de las tareas, tareas que no dejaban de ser familiares para ella por tratarse de la presentación de palabras con el objeto de ser leídas).
Las variables mediacionales también se controlaron, no hubo sobreaprendizaje pues cada sujeto sólo realizó cada prueba una vez, salvo los intentos de prueba, al mismo tiempo no se proporcionó feedback ni positivo ni negativo durante la realización de la misma.
Se crearon dos grupos en función del método de lectura mediante el cual estaban adquiriendo la lectura (analítico vs. sintético-fonético). A su vez los estímulos presentados se organizaron en función de 8 categorías diferentes fruto de la combinación de los tres factores anteriormente citados..
]]> Se midieron los tiempos de lectura (siempre de las palabras correctamente leídas) a través de un sistema de registro on-line a modo devariables dependientes.
Procedimiento
Se adaptó el programa on-line Gesmedición el cual permite el registro de las puntuaciones de lectura, tanto de la verificación (lectura correcta de las palabras) como de los tiempos de lectura.
Para la recogida de datos se instruyó al profesorado en cómo debería pasar el programa y así lo aplicó.
Finalmente, se analizaron los datos obtenidos mediante el promedio de cada uno de los grupos en función de los diferentes parámetros.
]]>
Resultados
En primer lugar se procedió al análisis de los datos a través de las medias de las puntuaciones en tasas de verificación (lectura de palabras) mostrados en las figuras de la 1 - 6 y tiempos de reacción en lectura analizados en las figuras de la 7 - 12.
1. Resultados en tareas de verificación (lectura de palabras)
Los sujetos que aprenden por un método sintético presentan una mayor tasa de aciertos en tareas de verificación en las palabras cortas y con frecuencia silábica alta por lo tanto siguen el mismo patrón que los del método global. Presentando una tasa menor tanto cortas como larga pero coincidiendo en frecuencia silábica posicional baja.
Apenas hay diferencias en el método global en función de la longitud y de la frecuencia silábica, siendo las puntuaciones más altas en palabras cortas y frecuencia silábica posicional (FSP) alta, así como, prácticamente iguales las medias en las otras tres condiciones.
Las diferencias entre ambos métodos son mayores en las palabras cortas y largas con FSP Baja de lo cual parece que podemos deducir la influencia que la condición FSP Baja es lo que más diferencia a ambos grupos en palabras con familiaridad alta.
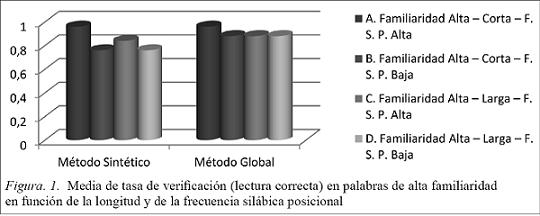
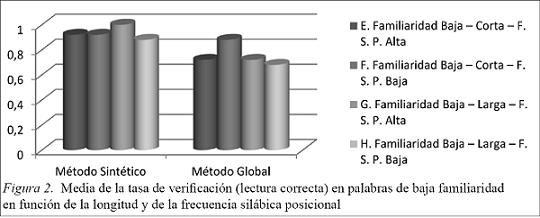
En la Figura 2 observamos que:
Los sujetos que recibieron un método sintético presentan tasas similares de respuesta a excepción de las palabras largas y FSP alta.
Los sujetos que recibieron un método global presentan una mayor tasa de verificación en las palabras cortas y de FSP baja frente a las otras condiciones que presentan una tasa media de respuesta similar.
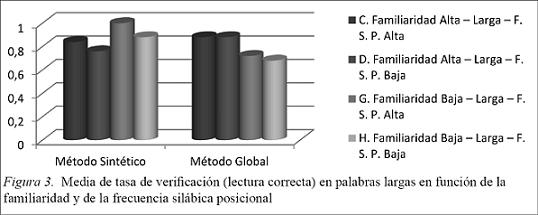
En la Figura 3 se muestra que:
En cuanto al método sintético encontramos que los datos más bajos se corresponden con la FSP Baja, siendo los de familiaridad baja mayores que los de familiaridad alta.
Hay resultados muy similares en el método global entre palabras con familiaridad alta y FSP alta y baja. Los resultados también son similares entre las palabras de familiaridad baja y FSP alta y baja. Comparando los resultados con alta y baja familiaridad estos últimos son los más bajos, siendo los Familiaridad Baja y FSP Baja los menores.
Comparando los datos de los dos métodos encontramos que leen mejor los del método global las palabras con familiaridad alta y los del método sintético las palabras con familiaridad baja. Aparecen similitudes en cuanto a la FSP donde son leídas mejor las palabras con FSP alta que las de baja en ambos grupos.
]]>
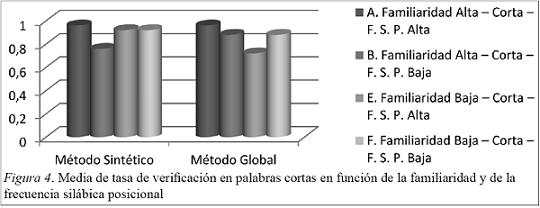
Como se puede apreciar en la Figura 4:
Los alumnos del método sintético presentan tasas similares de respuesta a excepción de las palabras con familiaridad baja y FSP baja. Destaca por encima la puntuación en función de la alta familiaridad y FSP alta.
Coincidiendo con el método sintético en el global también destaca por encima la puntuación en función de la alta familiaridad y FSP alta. Son muy similares los resultados con FSP baja y familiaridad alta y baja.
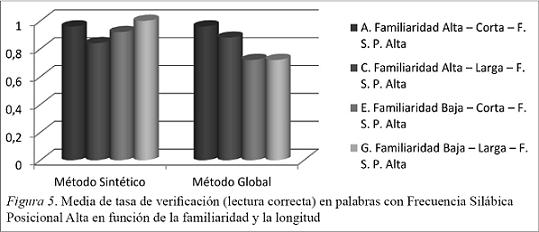
En la Figura 5 observamos que:
Los alumnos del método sintético obtienen mejores resultados en las palabras con familiaridad baja, siendo los mejores resultados los de las palabras con familiaridad baja y FSP alta.
Los alumnos del método global muestran mejores resultados en las palabras con familiaridad alta, siendo la mejor media la de las palabras con familiaridad alta y FSP alta.
Comparando los dos métodos los resultados en lectura de palabras familiares son similares mientras que los de las palabras no familiares son mejores en los alumnos del método sintético.
]]>
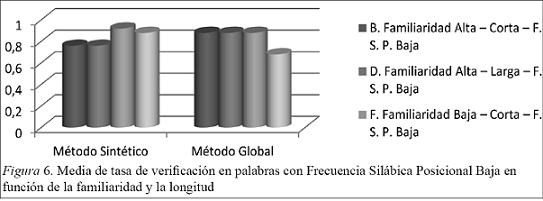
Finalmente en la Figura 6 podemos ver que:
Los alumnos del método sintético obtienen resultados muy similares entre las palabras de familiaridad alta y las palabras de familiaridad baja, siendo estos últimos unos resultados más altos.
Los resultados obtenidos por los alumnos del método global son muy similares a excepción de las palabras con familiaridad y FSP baja.
Comparando los dos grupos podemos concluir que no hay similitudes entre ellos.
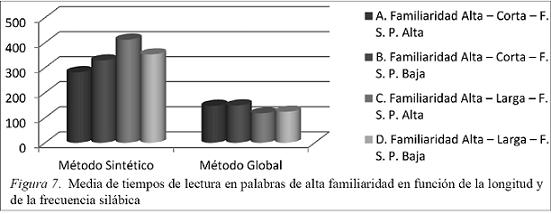
Como se puede apreciar en la Figura 7:
Los sujetos que aprenden por un método sintético presentan mejores tiempos de lectura en las palabras cortas que en las largas, siendo la mejor media de tiempos la de lectura de palabras cortas con FSP alta.
Los resultados de los alumnos que aprenden por el método global son muy similares entre las palabras cortas y entre las palabras largas, por lo que no influye la FSP. Son algo mayores los tiempos en lectura de palabras cortas que en el de las largas.
Comparando las medias de tiempos de los dos grupos podemos decir que hay una clara ventaja del grupo que aprende por el método global.
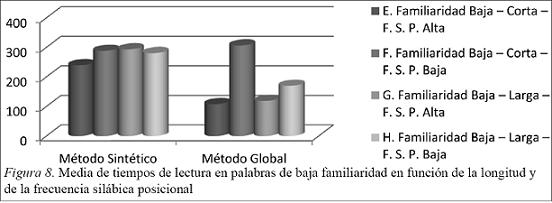
En la Figura 8 observamos que:
Los alumnos del método sintético tienen unas medias de tiempo similares a excepción de las palabras cortas y con FSP alta donde los tiempos de lectura son más cortos.
En el método global observamos tiempos más lentos en las palabras con FSP bajas, destacando los tiempos de lectura de palabras cortas y con FSP baja por ser mucho más lentos.
Si comparamos los dos grupos, el grupo que lee por el método global tiene mejores tiempos a excepción del parámetro ya comentado de palabras con familiaridad baja y FSP baja.
]]>
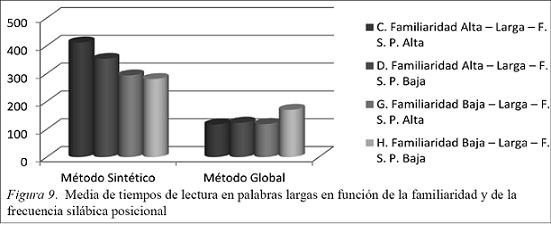
En la Figura 9 se muestra que:
Los alumnos del método sintético tienen mejores tiempos cuando la palabra a leer tiene una familiaridad baja que cuando es alta. Además se observa que los tiempos son mejores en palabras con FSP baja que alta.
El alumnado del método global presenta unos tiempos de lectura más altos en palabras con familiaridad baja y de FSP baja frente a las otras condiciones que presentan una tasa media de respuesta similar.
Comparando los dos grupos existen unas mejores medias a favor del grupo que aprende por el método global en los 4 parámetros.
]]>
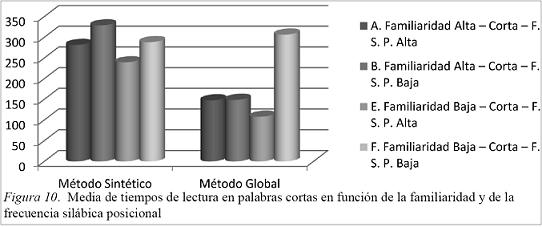
En la Figura 10 observamos que:
Los alumnos del método sintético tienen mejores tiempos en palabas con FSP alta que en las de baja FSP. La lectura de palabras con familiaridad baja tiene mejores tiempos que la de familiaridad alta.
A penas hay diferencias en el método global entre las palabras con familiaridad alta y FSP alta y baja. Cuando se trata de las palabras de baja familiaridad los tiempos se incrementan en gran medida en las de FSP baja.
La comparación de los dos métodos da lugar a mejores tiempos para el método global a excepción del parámetro familiaridad baja y FSP baja.
]]>
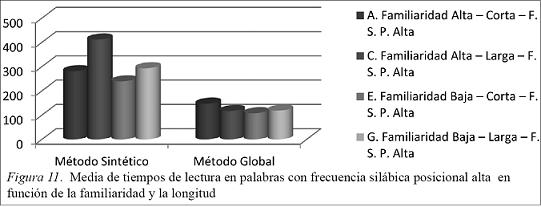
Como se puede apreciar en la Figura 11:
Los alumnos del método sintético tienen una media de tiempo más lenta en palabras largas, siendo las palabras largas y de familiaridad alta las más lentas.
Los alumnos del método global obtuvieron unas medias similares donde las palabras cortas y de familiaridad alta tiene la media más lenta.
La comparación de las medias de los dos grupos da como resultado que el grupo que aprende por el método global es el que obtuvo unos tiempos más bajos en lectura de palabras de los 4 parámetros.
]]>
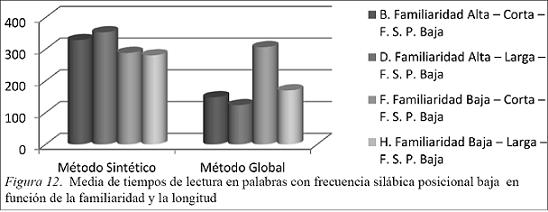
En la Figura 12 observamos que:
Los alumnos del método sintético leen más lentamente las palabras de familiaridad alta, siendo las de familiaridad alta y FSP baja las más lentas.
Los alumnos del método global obtienen unos tiempos más cortos en lectura de palabras familiares que en palabras poco familiares. Es destacable la media de tiempos de lectura de las palabras de familiaridad baja y cortas por sus tiempos tan lentos.
Al comparar los dos grupos los resultados indican que el grupo que aprende por el método global tiene unos tiempos más cortos que el del método sintético, a excepción del parámetro familiaridad baja y palabra corta.
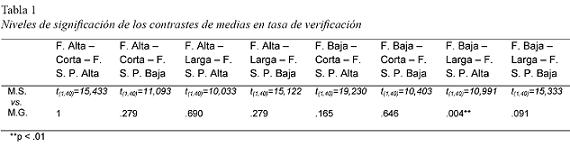
Para comprobar el nivel de significación de las distintas puntuaciones intergrupo procedimos a la aplicación de la prueba t-Student para contrastar las medias y comprobar el nivel de significación estadística. Los resultados de dichos contrastes:
La tabla 1 muestra que las diferencias (en las tareas de verificación) entre ambos grupos sólo alcanzan el nivel de significatividad en las palabras con los parámetros: Familiaridad Baja – Larga – F. S. P. Alta a favor del método sintético.
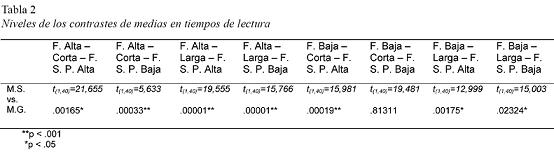
La Tabla 2 muestra los contrastes entre tiempos de reacción y observamos que se alcanza el nivel de significatividad en todas las condiciones excepto en el parámetro F. Familiaridad Baja – Corta – F. S. P. Baja:
Encontramos diferencias significativas a un nivel p < .001 en las condiciones B, C, D y E a favor del método global.
Encontramos diferencias significativas a un nivel p < .05 en las condiciones A, G y H también a favor del método global.
Discusión
Se comienza esta discusión comentando la influencia que han tenido los distintos parámetros psicolingüísticos utilizados.
El efecto de la frecuencia léxica ha sido el esperado ya que la hipótesis planteada fue que en cuanto a la frecuencia léxica alta no habría diferencias significativas y que sí se encontrarían en la frecuencia léxica baja con mejores resultados en los alumnos que aprenden por el método sintético-fonético, esto fue prácticamente así. Por una parte los resultados confirman la primera premisa referente a que la frecuencia léxica alta no da diferencias significativas intergrupo y, en cuanto a la frecuencia léxica baja se encontraron diferencias significativas siendo la inclinación más favorable hacia los métodos sintéticos en cuanto a tasas de verificación. Este resultado es coincidente con el estudio de Cuetos y Suárez-Coalla (2009).
En referencia al parámetro de longitud, se había planteado que sólo influiría en los tiempos de lectura en palabras de baja frecuencia léxica y así fue, no se mostraron diferencias en cuanto a la tasa de verificación y sí en los tiempos de lectura de las palabras con FSP baja, pero únicamente se mostraron estas diferencias en el método global. Como indican Cuetos y Suárez-Coalla (2009) “los resultados en términos de precisión y la velocidad de lectura mostraron que la influencia de la longitud de estímulo es grande en los primeros años”. El incremento del tiempo en palabras largas es debido a que un mayor número de grafemas exige un mayor número de aplicaciones de reglas de transformación grafema-fonema, lo que supone un incremento en el tiempo de lectura (Guzmán, 1997). Esta autora encontró también diferencias en cuanto a que los que aprenden por el método sintético cometen menos errores cuando las palabras son largas. Interpreta este dato a que el método fonético se consigue un mayor desarrollo de la estrategia fonológica en lectura, esto hace que estos alumnos son más eficientes en el análisis subléxico de las palabras largas.
En cuanto al parámetro de frecuencia silábica posicional (FSP), se había planteado que sólo afectaría al método sintético tanto en la verificación como en los tiempos de lectura y así fue, los resultados de esta investigación indican que la FSP baja influye en las estrategias de acceso al léxico, independientemente de otras variables, en el grupo que aprende por el método sintético.
En cuanto a los tiempos de lectura se consideraron dos hipótesis, la primera fue que habría diferencias significativas en palabras con baja frecuencia léxica y la segunda fue que los tiempos serían mayores en el método sintético-fonético. En cuanto a la primera hipótesis, se encontraron las diferencias esperadas pero únicamente en los alumnos que aprendían por el método global. La segunda hipótesis se corroboró en el análisis de todos los resultados ya que el tiempo de lectura del método global fue siempre más bajo a excepción del parámetro F. Familiaridad Baja, palabras cortas y FSP baja. Esto pudo ser debido a la influencia de la FSP baja ya comentada, pues las otras dos variables no parecen beneficiar a este método, sino todo contrario, tal y como se puede observar en el resto de combinaciones. Según este dato, la FSP baja parece discriminar la eficacia entre ambos métodos.
Por todo esto, podemos concluir que la influencia de los métodos de lectura, sobre las estrategias utilizadas en el acceso al léxico, se refleja en los resultados obtenidos, sobre todo teniendo en cuenta el tiempo de respuesta y la tasa de verificación conjuntamente. En efecto, los alumnos del método sintético muestran mayor tasa de verificación, habiendo unos resultados más bajos cuando se trata de los parámetros que incluyen FSP Baja, siendo significativo el parámetro G. Familiaridad Baja-Larga- FSP Alta y, en general, con unos tiempos de lectura más lentos en todos ellos. Por el contrario, los estudiantes que aprenden por el método global tienen una tasa de verificación algo más baja pero los tiempos de lectura son significativamente más rápidos en casi todos los parámetros.
Estas conclusiones son similares a las extraídas por Guzmán (1997) quien encuentra que el método de lectura influye en el acceso al léxico en el sentido de que los alumnos del método fonético automatizan mejor el acceso al significado de las palabras en comparación con los alumnos del método global-natural.
Los principales resultados de este estudio son:
A la luz de los resultados y de las puntuaciones en tasa de verificación podemos decir que no existe un método mejor que el otro.
A la hora de tiempos de lectura, en condiciones de longitud y frecuencia o familiaridad son más rápidos los sometidos a un método analítico. Este último dato ha de ser tomado e interpretado con cautela, en el sentido de que hemos de tener en cuenta que la población participante en este estudio no ha alcanzado la etapa ortográfica (aquella en la cual el lector posee representaciones globales grafémicas ortográficamente correctas) que supondría la etapa experta del lector sometido a un método sintético-fonético.
Aunque sí cabe destacar que la rapidez en lectura beneficia al procesamiento cognitivo en el sentido de que los procesos ejecutivos no se ven sobrecargados. Un aspecto que en los niños con dificultades de aprendizaje de la lectura mediatiza el éxito lector.
Además se puede extraer de los resultados de este estudio que el método de lectura influye en las estrategias de acceso al léxico, lo que deriva en uno de las aportaciones más importantes de esta investigación, por las implicaciones educativas que puede tener, y es que deben de tenerse en cuenta ciertas características de la palabra a la hora de instruir y evaluar en un método sintético-fonético y en un método analítico o global, sobre todo en lo relativo a la frecuencia silábica posicional a la hora de una lectura correcta de las palabras y la familiaridad, la longitud y la frecuencia silábica posicional en la velocidad lectora.
Alegria, J., Pignot, E., & Morais, J. (1982). Phonetic analysis of speech and memory codes in beginning readers. Memory y Cognition, 10(5), 451-456.
Alvarez C.J., Carreiras, M., & de Vega, M. (1992). Estudios estadísticos de la ortografía Castellana: (1) la frecuencia silábica. Cognitiva, 4, 75-105.
Ashby, J., & Martin, A. E. (2008). Prosodic phonological representations early in visual word recognition.Journal of Experimental Psychology: Human Perception and Performance, Vol 34(1), 224-236.
Cuetos, F. (1990). Psicología de la lectura. Madrid: Escuela Española.
Cuetos, F. & Suárez-Coalla, P. (2009). From grapheme to word in learning to read in Spanish. AppliedPsycholinguistics, 30, 583-601.
Domínguez, A. & Cuetos, F. (1992). Desarrollo de las habilidades de reconocimiento de palabras en niños con distinta competencia lectora. Cognitiva, 4, (2), 193-208.
Galera, F. (2009). La enseñanza de la lectura y la escritura: Teoría y Práctica. Granada: Grupo Editorial Universitario.
Gollan, T. H., Slattery, T. J., Goldenberg, D., Van Assche, E., Duyck, W., & Rayner, K. (2011) Frequency drives lexical access in reading but not in speaking: The frequency-lag hypothesis.Journal of Experimental Psychology: General, 140(2), 186-209.
Goswami, U. C., & Bryant, P. (1990). Phonological skills and learning to read. Psychology Press.
Guzmán, R. (1997). Métodos de lectura y acceso al léxico (Tesis doctoral). Universidad de La Laguna, España.
Hoien-Tengesdal, I. yHoien, T. (2012) The Reading Efficiency Model: An Extension of the Componential Model of Reading. Journal of Learning Disabilities, 45, 480-486.
Kewaza, S. y Welch, Myrtle I. (2013). Big Class Size Challenges: Teaching Reading in Primary Classes in Kampala, Uganda’s Central Municipality. Journal ofUS-China Education Review, 3, 283-296.
Morton, J. (1980). The logogen model and orthographic structure. In U. Frith (Ed.), Cognitive processes in spelling. London: Academic Dress.
Morton, J. & Paterson, K.E. (1980). A new attempt at an interpretation, or, an a attempt at a new interpretation. In M. Coltheart, K.E. Patterson & J.C. Marshall (Eds.). Deep dyslexia (pp. 91-118). London: Routledge & Keplan, Paul.
]]>Patterson, K. & Shewell, C. (1987). Speak and spell: Dissociations and word-class effects. In M. Coltheart, G. Sartori, & R. Job (Eds.). The cognitive neuropsychology of language ( pp. 273-394). London: Erlbaum.
Perfetti, C. A., Beck, I., Bell, L. C., & Hughes, C. (1987). Phonemic knowledge and learning to read are reciprocal: A longitudinal study of first grade children. Merrill-Palmer Quarterly (1982-), 283-319.
Sowden, P. T. & Stevenson, J. (1994). Beginning reading strategies in children experiencing contrasting teaching methods. Reading and Writing, 6(2), 109-123.
Stanovich, K.E. (2000). Progress in Understanding Reading. New York: Guilford Press.
Vannorsdall, T.D., Maroof, D.A., Gordon, B. ySchretlen, D.J. (2012). Ideational fluency as a domain of human cognition.Neuropsychology, Vol 26(3), 400-405.
]]>Venezky, R. (1978). Two approaches to reading assessment: A comparison of apples and oranges. Aspects of reading instruction. Berkeley, CA: McCutcheon.
Wang, Ch. & Inhoff, A.W. (2013).Extraction of linguistic information from successive words during reading: Evidence for spatially distributed lexical processing.Journal of Experimental Psychology: Human Perception and Performance, 39(3), 662-677.
Para citar este artículo:
Villar, D. & Vieiro, P. (2015). Métodos de lectura y acceso léxico on-line en lectores principiantes. Ciencias Psicológicas, 9(2), 309 - 319.
]]>