 in the last 5 years [ 2]), the ambitious goal of yielding a sustained ExaFLOPS (i.e.,
in the last 5 years [ 2]), the ambitious goal of yielding a sustained ExaFLOPS (i.e., 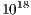 floating-point arithmetic operations, or flops, per second) for 20–40 MWatts by the end of this decade will be clearly exceeded.
floating-point arithmetic operations, or flops, per second) for 20–40 MWatts by the end of this decade will be clearly exceeded.
Abstract
We analyze the performance-power-energy balance of a conventional Intel Xeon multicore processor and two low-power architectures –an Intel Atom processor and a system with a quad-core ARM Cortex A9+NVIDIA Quadro 1000M– using a high performance implementation of Gauss-Jordan elimination (GJE) for matrix inversion. The blocked version of this algorithm employed in the experimental evaluation mostly comprises matrix-matrix products, so that the results from the evaluation carry beyond the simple matrix inversion and are representative for a wide variety of dense linear algebra operations/codes. ]]>
ResumenEn este trabajo se estudia el desempeño, potencia y consumo energético necesario al utilizar un procesador convencional Intel Xeon multi-core y dos arquitecturas de bajo consumo -como son el procesador Intel Atom y un sistema con un procesador ARM quad-core Cortex A9 conectado a una GPU NVIDIA Quadro 1000M- para computar la inversión de matrices mediante una implementación optimizada del algoritmo de eliminación de Gauss-Jordan (GJE). El algoritmo a bloques utilizado para realizar la evaluación experimental se basa fuertemente en la operación producto matriz-matriz, por lo tanto los resultados obtenidos no solo son aplicables a la inversión de matrices, sino que, son representativos para una gama amplia de operaciones de álgebra lineal densa.
Keywords: Dense Linear Algebra, Gauss–Jordan, Power, Energy
Spanish keywords: Álgebra lineal densa, Gauss-Jordan, Energía
Received 2013-09-08, Revised 2014-03-10, Accepted 2014-03-10
General-purpose multicore architectures and graphics processor units (GPUs) dominate today’s landscape of high performance computing (HPC), offering unprecedented levels of raw performance when aggregated to build the systems of the Top500 list [ 1]. While the performance-power trade-off of HPC platforms has also enjoyed considerable advances in the past few years [ 2] —mostly due to the deployment of heterogeneous platforms equipped with hardware accelerators (e.g., NVIDIA and AMD graphics processors, Intel Xeon Phi) or the adoption of low-power multicore processors (IBM PowerPC A2, ARM chips, etc.)— much remains to be done from the perspective of energy efficiency. In particular, power consumption has been identified as a key challenge that will have to be confronted to render Exascale systems feasible by 2020 [ 3, 4, 5]. Even if the current progress pace of the performance-power ratio can be maintained (a factor of about in the last 5 years [ 2]), the ambitious goal of yielding a sustained ExaFLOPS (i.e., floating-point arithmetic operations, or flops, per second) for 20–40 MWatts by the end of this decade will be clearly exceeded.
In recent years, a number of HPC prototypes have proposed the use of low-power technology, initially designed for mobile appliances like smart phones and tablets, to deliver high MFLOPS/Watt rates [ 6, 7]. Following this trend, in this paper we investigate the performance, power and energy consumption of two low-power architectures, concretely an Intel Atom and a hybrid system composed of a multicore ARM processor and an NVIDIA 96-core GPU, and a general-purpose multicore processor, using as a workhorse matrix inversion via Gauss-Jordan elimination (GJE) [ 8]. While this operation is key for the solution of important matrix equations arising in control theory via the matrix sign function [ 9, 10], the relevance of this study carries beyond the inversion operation/method or these specific applications. In particular, a blocked implementation of matrix inversion via GJE casts the bulk of the computations in terms of the matrix-matrix product, so that its performance as well as power dissipation and energy consumption are representative for many other dense linear algebra operations such as, e.g., the solution of linear systems, linear-least squares problems, eigenvalue computations, etc.
The rest of the paper is structured as follows. In Section 2 we briefly review matrix inversion via the GJE method and an applications of this particular operation. Specifically, we introduce the sign function, which plays an important role for the resolution of several scientific problems arising in control theory. Next, in Section 3, we describe the specific implementation of the GJE method on the two low-power architectures selected for our study: i) an Intel Atom processor not much different, from the programming point of view, from a mainstream multicore processor like the Intel Xeon or the AMD Opteron; and ii) a hybrid board with ARM+NVIDIA technology that can be viewed as a low-power version of the heterogeneous platforms equipped with hardware accelerators that populate the first positions of the Top500 list. Finally, Sections 4 and 5 contain, respectively, the experimental evaluation and a few concluding remarks resulting from this investigation.
]]>
2 Matrix Inversion via GJE and its Applications to Control TheoryThe traditional approache to compute a matrix inverse is based on the LU factorization and consist of the following three steps:
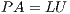 , where
, where 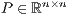 is a permutation matrix, and
is a permutation matrix, and 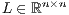 and
and 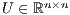 are, respectively, unit lower and upper triangular factors [ 11].
are, respectively, unit lower and upper triangular factors [ 11]. 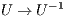 .
. 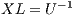 for
for 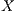 .
. 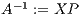 .
.An alternative approach to compute a matrix inverse is the GJE, an appealing method for matrix inversion in current architecture, becauase it presents a computational cost and numerical properties analogous to those of traditional approaches [ 8] but superior performance on a variety of parallel architectures, including clusters [ 12], general-purpose multicore processors and GPUs [ 9].
Figure 1 shows a blocked version of the GJE algorithm for matrix inversion using the FLAME notation. There 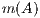 stands for the number of rows of matrix
stands for the number of rows of matrix  while, for details on the notation, we refer the reader to [ 13, 14]. A description of the unblocked version of GJE, called from inside the blocked routine, can be found in [ 12]; for simplicity, we do not include the application of pivoting during the factorization, but details can be found there as well. Given a square (nonsingular) matrix of size
while, for details on the notation, we refer the reader to [ 13, 14]. A description of the unblocked version of GJE, called from inside the blocked routine, can be found in [ 12]; for simplicity, we do not include the application of pivoting during the factorization, but details can be found there as well. Given a square (nonsingular) matrix of size 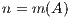 , the cost of matrix inversion using this algorithm is
, the cost of matrix inversion using this algorithm is 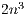 flops, performing the inversion in-place so that, upon completion, the entries of
flops, performing the inversion in-place so that, upon completion, the entries of 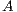 are overwritten with those of its inverse.
are overwritten with those of its inverse.
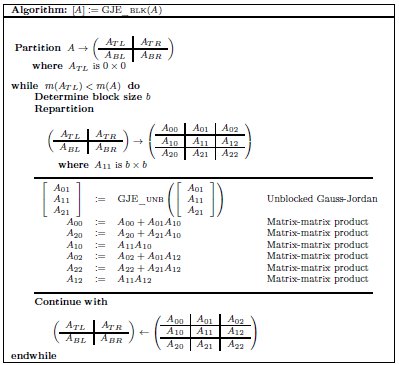
Our primary interest for the GJE matrix inversion method is twofold. First, most of the computations of the blocked algorithm are matrix-matrix products (see Figure 1). Therefore, the conclusions from our power–energy–performance evaluation can be extended to many other dense linear algebra kernels such as the solution of linear systems via the LU and Cholesky factorizations, and least-squares computations using the QR factorization [ 11], among others.
Additionally, explicit matrix inversion is required during the computation of the sign function of a matrix 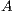 using the Newton iteration method [ 10], which we describe brief in the next sub-section.
using the Newton iteration method [ 10], which we describe brief in the next sub-section.
Consider a matrix 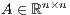 with no eigenvalues on the imaginary axis, and let
with no eigenvalues on the imaginary axis, and let
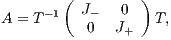 | (1) |
be its Jordan decomposition, where the eigenvalues of 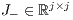 and
and 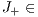
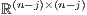 have negative and positive real parts [ 11] respectively.
have negative and positive real parts [ 11] respectively.
The matrix sign function of 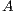 is then defined as
is then defined as
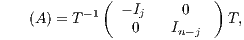 | (2) |
where 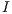 denotes the identity matrix of the order indicated by the subscript. The matrix sign function is a useful numerical tool for the solution of control theory problems (model reduction, optimal control) [ 15], and the bottleneck computation in many lattice quantum chromodynamics computations [ 16] and dense linear algebra computations (block diagonalization, eigenspectrum separation) [ 11, 17]. Large-scale problems as those arising, e.g., in control theory often involve matrices of dimension
denotes the identity matrix of the order indicated by the subscript. The matrix sign function is a useful numerical tool for the solution of control theory problems (model reduction, optimal control) [ 15], and the bottleneck computation in many lattice quantum chromodynamics computations [ 16] and dense linear algebra computations (block diagonalization, eigenspectrum separation) [ 11, 17]. Large-scale problems as those arising, e.g., in control theory often involve matrices of dimension 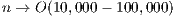 [ 18].
[ 18].
There are simple iterative schemes for the computation of the sign function. Among these, the Newton iteration, given by
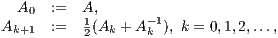 | (3) |
]]>
is specially appealing for its simplicity, efficiency, parallel performance, and asymptotic quadratic convergence [ 17, 19, 20]. However, even if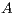 is sparse,
is sparse, 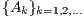 are in general full dense matrices and, thus, the scheme in (3) roughly requires
are in general full dense matrices and, thus, the scheme in (3) roughly requires 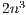 floating-point arithmetic operations (flops) per iteration.
floating-point arithmetic operations (flops) per iteration.
3 High Performance Implementation of GJE on Multicore and Manycore Architectures
As previously stated, the GJE algorithm for matrix inversion casts the bulk of the computations in terms of matrix-matrix products; see Figure 1. In particular, provided that the block size 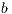 is chosen there as
is chosen there as 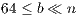 , the computational cost of the factorization of the “current” panel
, the computational cost of the factorization of the “current” panel ![ˆ [ T T T ]T A = A01;A11;A21](/img/revistas/cleiej/v17n1/1a0432x.png) , performed inside the routine GJE_UNB, is negligible compared with that of the update of the remaining matrix blocks following that operation.
, performed inside the routine GJE_UNB, is negligible compared with that of the update of the remaining matrix blocks following that operation.
Therefore, the key to attaining high performance with GJE algorithm primarily relies on using a highly tuned implementation of the matrix-matrix product and, under certain conditions on parallel architectures, the reduction of the serial bottleneck that the factorization of 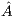 represents applying, e.g., a look-ahead strategy [ 21].
represents applying, e.g., a look-ahead strategy [ 21].
Fortunately, there exist nowadays highly efficient routines for the matrix-matrix multiplication, embedded into mathematical libraries such as Intel MKL, AMD ACML, IBM ESSL, or NVIDIA CUBLAS; but also as part of independent development efforts like GotoBLAS2 [ 22] or OpenBLAS [ 23]. Therefore, for the implementation of GJE in the Atom processor (as well as for the Intel Xeon processor that will be used for reference in the experimental evaluation), we simply leverage the matrix-matrix product kernel sgemm in a recent version of Intel MKL.
Let us consider next the hybrid SECO development kit [ 24], which combines a quad-core NVIDIA Tegra3/ARM Cortex A9 processor and an NVIDIA Quadro 1000M GPU with 96 cores, both processors in single board (see Figure 2).
The properties of the GJE algorithm and the hybrid nature of the target platform ask for an implementation that harnesses the concurrency of the operation while paying special attention to diminish the negative impact of communications between the memory address spaces of the Cortex A9 processor and the Quadro GPU. In a previous work we introduced a CPU-GPU implementation of the GJE algorithm for matrix inversion [ 9], and demonstrated the benefits of mapping each operation to the most convenient device: multicore processor or manycore accelerator. In this work we apply a similar approach to obtain a tuned implementation of the GJE algorithm for the SECO platform. The highly parallel matrix-matrix products are computed in the GPU. On the other hand, the panel factorizations performed with the unblocked algorithm GJE_UNB, which consist of fine grain operations, are computed in the multicore CPU. This algorithm is summarized in Figure 3 (note that, for simplicity, pivoting is ommitted in the figure, though partial column pivoting is performed in all our implementations). The block size 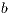 is tuned for the architecture and also for each problem dimension.
is tuned for the architecture and also for each problem dimension.
Additionally, we include a look-ahead technique that allows to overlap the factorization in step 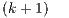 with part of the updates performed during iteration
with part of the updates performed during iteration 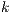 , and also keeps a low communication overhead.
, and also keeps a low communication overhead.
Finally, the parallelism intrinsic to the linear algebra operations that appear in algorithms GJE_BLK and GJE_UNB are exploited using parallel implementations of the BLAS. In particular, we employ kernels from libraries CUBLAS and reference BLAS (parallelized with OpenMP directives), for the Quadro GPU and the ARM processor respectively.

This section is divided into three parts. First, we introduce the target platforms. This is followed by a description of the power measurement system. Finally, the results obtained are presented and analyzed.
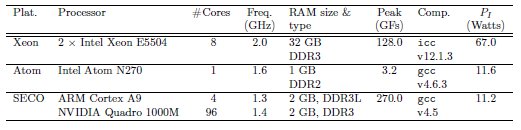
We evaluate the matrix inversion routines on three target hardware platforms: a state-of-the-art server equipped with two multicore Intel Xeon (“Nehalem”) processors, an Intel Atom-based laptop, and a hybrid ARM+NVIDIA board from SECO. Details about the hardware and the compilers employed in each platform can be found in Table 1.
The inversion routines for the Xeon and Atom processors heavily rely on the matrix-matrix product kernel in Intel MKL (versions 10.3 and 11.0, respectively). The hybrid implementation for the SECO platform makes intensive use of the kernels in CUBLAS (version 5.0) and the legacy implementation of BLAS (available at http://www.netlib.org/). parallelized with OpenMP. (We note, however, that the amount of computation that is performed in the cores of the Cortex A9 processor is small, and mostly based on BLAS-1 and BLAS-2 operations, so that we do not expect significant differences if a tuned version of BLAS was used for this architecture.)
The codes were compiled with the -O3 optimization flag and all the computations were performed using single precision arithmetic.
]]>
 )
)
In order to measure power, we connected a WATTSUP?PRO wattmeter (accuracy of 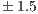 % and a rate of 1 sample/sec.) to the power line from the electric socket to the power supply unit (PSU), collecting the results on a separate server. All tests were executed for a minimum of 1 minute, after a warm up period of 2 minutes.
% and a rate of 1 sample/sec.) to the power line from the electric socket to the power supply unit (PSU), collecting the results on a separate server. All tests were executed for a minimum of 1 minute, after a warm up period of 2 minutes.
Since some of the platforms where the processors are embedded contain other devices —e.g., disks, network interface cards, and on the Atom laptop even the LCD display— on each platform we calculated the average power while idle for 1 minute, 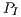 , and then used this value to calculate the net energy, corresponding to the consumption after subtracting
, and then used this value to calculate the net energy, corresponding to the consumption after subtracting 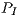 from the power samples. We expect this measure allows a fair comparison between the architectures, as in this manner we only evaluate the energy that is necessary to do the actual work. ]]>
from the power samples. We expect this measure allows a fair comparison between the architectures, as in this manner we only evaluate the energy that is necessary to do the actual work. ]]>
The experimental evaluation is performed in two stages. First, we analyze the performance and power-energy consumption of the GJE for matrix inversion algorithm. Next, we study the impact of Gauss-Jordan inversion method on the resolution of matrix sign function.
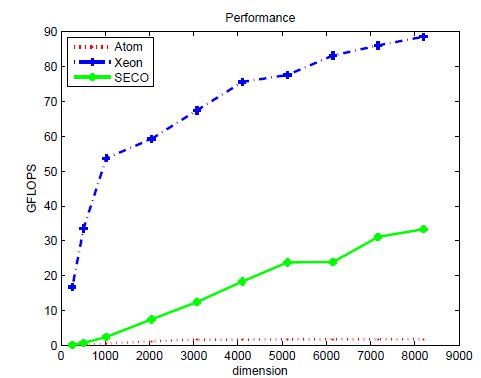
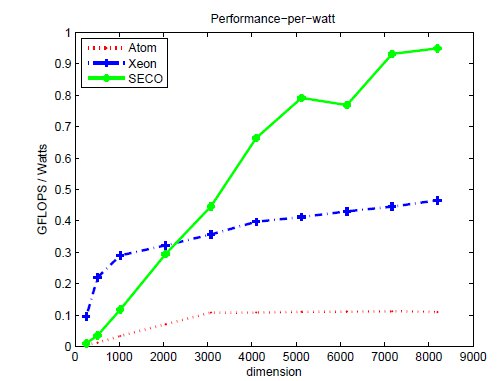
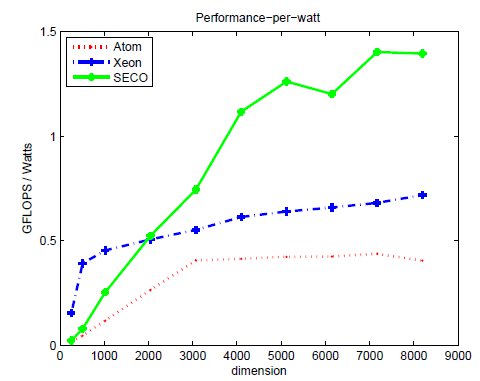
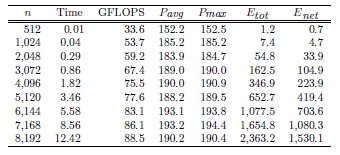
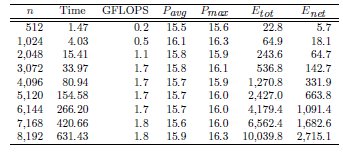
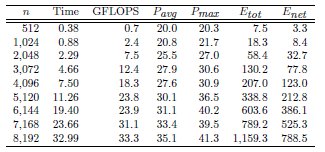
Tables 2, 3 and 4 collect the results obtained from the execution of the different implementations of the GJE matrix inversion algorithm on the three target platforms, for problems of dimension 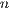 varying from 256 to 8,192. The same information is refined and collected graphically, in terms of GFLOPS and GFLOPS/Watt, in Figures 4, 5 and 6.
varying from 256 to 8,192. The same information is refined and collected graphically, in terms of GFLOPS and GFLOPS/Watt, in Figures 4, 5 and 6.
The results characterize the different performance-power-energy balance of the platforms: The Intel Xeon is considerably faster than the Intel Atom, in factors that range from more than 255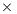 for the smaller problem dimensions, to about 50.8
for the smaller problem dimensions, to about 50.8 for the larger ones; but the power dissipated by the Atom architecture is, depending on the problem size, 9.8 to 12.4
for the larger ones; but the power dissipated by the Atom architecture is, depending on the problem size, 9.8 to 12.4 lower than that of the Intel Xeon architecture. The outcome of the combination of these two factors is that, from the perspective of total energy, the Intel Atom spends between 4.25 and 22.0
lower than that of the Intel Xeon architecture. The outcome of the combination of these two factors is that, from the perspective of total energy, the Intel Atom spends between 4.25 and 22.0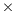 more energy than the Intel Xeon to compute the inverse; but the excess is only between 1.77 and 8.46
more energy than the Intel Xeon to compute the inverse; but the excess is only between 1.77 and 8.46 if we consider net energy. On the other hand, the SECO board presents quite an interesting balance. While being clearly slower than the Intel Xeon (especially for the smaller problems), this platform also shows a remarkable advantage from the point of view of energy efficiency. Thus, when the problem size is larger than 2,048, the ratios for the total and net energy of these two platforms are, respectively, up to 2.04 and 1.94
if we consider net energy. On the other hand, the SECO board presents quite an interesting balance. While being clearly slower than the Intel Xeon (especially for the smaller problems), this platform also shows a remarkable advantage from the point of view of energy efficiency. Thus, when the problem size is larger than 2,048, the ratios for the total and net energy of these two platforms are, respectively, up to 2.04 and 1.94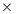 in favor of the SECO system.
in favor of the SECO system.
]]>
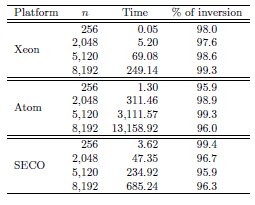
The time evaluation summarized in Table 5 shows the close relation between the computational complexity of the matrix sign function algorithm and the matrix inversion kernel. Thus, the time required by the computation of the matrix inverses represents at least the 95% of the computational time of the overall process. This allows to easily compute a rough approximation of the energy consumption from the data obtained during the matrix inversion kernels evaluation. In particular, Table 6 summarizes the total runtime (in seconds) and the energy consumption (in Joules) for the computation of the matrix sign function on the three platforms and four different dimension cases (256, 2,048, 5,120 and 8,192).
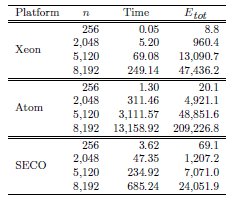
The highest energy consumption is required by Atom. Despite its low average power consumption, the large computational time leads to the worst results in terms of energy for this platform. Thus, the energy consumed by the Xeon is 4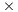 lower for the largest problem tackled. On the other hand the lowest energy consumption is obtained for SECO, which requires 2
lower for the largest problem tackled. On the other hand the lowest energy consumption is obtained for SECO, which requires 2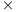 and 8
and 8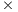 less energy than Xeon and Atom respectively. This is explained by the favorable performance-power ratio of the SECO platform.
less energy than Xeon and Atom respectively. This is explained by the favorable performance-power ratio of the SECO platform.
5 Concluding Remarks and Future Directions
We have investigated the trade-off between performance and power-energy of three architectures using as a benchmark the matrix sign function, a useful mathematical tool in some numerical methods. In particular, the evaluation includes two low-power architectures and a conventional general-purpose multicore processor.
Our experimental evaluation is divided in two stages. First, the main computational kernel in the sign function algorithm, the general matrix inversion, is evaluated. Then, the complete sign function algorithm is assessed. ]]>
The use of blocked routines for GJE matrix inversion shows that, for dense linear algebra operations that are rich in matrix-matrix products, the race-to-idle strategy (i.e, execute the task as fast as possible, even if there is a high power dissipation associated with that) is crucial to attain both high throughput and performance-per-watt rates on general-purpose processor architectures, favoring power-hungry complex designs like the Intel Xeon processor over the Intel Atom counterpart. However, the experimentation also shows that a hybrid architecture that combines a low-power multicore processor and a limited GPU can offer competitive performance compared with that of the Intel Xeon platform, while being clearly superior from the perspective of energy efficiency.The results obtained during the evaluation of the matrix sign function reinforce the conclussions extracted from the previous analisys.
Future research lines resulting from this experience will include:
The researcher from UJI was supported by the CICYT project TIN2011-23283 of the Ministerio de Economía y Competitividad, FEDER, and the EU Project FP7 318793 “EXA2GREEN”. P. Ezzatti acknowledges support from Agencia Nacional de Investigación e Innovación (ANII) and Programa de Desarrollo de las Ciencias Básicas (PEDECIBA), Uruguay. The authors gratefully acknowledge Juan Pablo Silva and Germán León for their technical support with SECO hardware platform.
]]>
[1] “The top500 list,” 2013, available at http://www.top500.org.
[2] “The Green500 list,” 2013, available at http://www.green500.org.
[3] S. Ashby et al, “The opportunities and challenges of Exascale computing,” Summary Report of the Advanced Scientific Computing Advisory Committee (ASCAC) Subcommittee, November 2010. [Online]. Available: http://science.energy.gov/~/media/ascr/ascac/pdf/reports/Exascale\_subcommittee\_report.pdf
[4] J. Dongarra and et al, “The international ExaScale software project roadmap,” Int. J. of High Performance Computing & Applications, vol. 25, no. 1, pp. 3–60, 2011.
[5] M. Duranton and et al, “The HiPEAC vision for advanced computing in horizon 2020,” 2013.
[6] “CRESTA: collaborative research into Exascale systemware, tools and applications,” http://cresta-project.eu.
[7] “The Mont Blanc project,” http://montblanc-project.eu.
[8] N. Higham, Accuracy and Stability of Numerical Algorithms, 2nd ed. Philadelphia, PA, USA: Society for Industrial and Applied Mathematics, 2002.
[9] P. Benner, P. Ezzatti, E. S. Quintana-Ortí, and A. Remón, “Matrix inversion on CPU-GPU platforms with applications in control theory,” Concurrency and Computation: Practice & Experience, vol. 25, no. 8, pp. 1170–1182, 2013. [Online]. Available: http://dx.doi.org/10.1002/cpe.2933
]]> [10] J. Roberts, “Linear model reduction and solution of the algebraic Riccati equation by use of the sign function,” Internat. J. Control, vol. 32, pp. 677–687, 1980, (Reprint of Technical Report No. TR-13, CUED/B-Control, Cambridge University, Engineering Department, 1971).[11] G. Golub and C. V. Loan, Matrix Computations, 3rd ed. Baltimore: The Johns Hopkins University Press, 1996.
[12] E. Quintana-Ortí, G. Quintana-Ortí, X. Sun, and R. van de Geijn, “A note on parallel matrix inversion,” SIAM J. Sci. Comput., vol. 22, pp. 1762–1771, 2001.
[13] P. Bientinesi, J. A. Gunnels, M. E. Myers, E. S. Quintana-Ortí, and R. A. van de Geijn, “The science of deriving dense linear algebra algorithms,” ACM Trans. Math. Soft., vol. 31, no. 1, pp. 1–26, March 2005. [Online]. Available: http://doi.acm.org/10.1145/1055531.1055532
[14] J. A. Gunnels, F. G. Gustavson, G. M. Henry, and R. A. van de Geijn, “FLAME: Formal linear algebra methods environment,” ACM Trans. Math. Soft., vol. 27, no. 4, pp. 422–455, Dec. 2001. [Online]. Available: http://doi.acm.org/10.1145/504210.504213
[15] P. Petkov, N. Christov, and M. Konstantinov, Computational Methods for Linear Control Systems. Hertfordshire, UK: Prentice-Hall, 1991.
[16] A. Frommer, T. Lippert, B. Medeke, and K. Schilling, Eds., Numerical Challenges in Lattice Quantum Chromodynamics, ser. Lecture Notes in Computational Science and Engineering. Berlin/Heidelberg: Springer-Verlag, 2000, vol. 15.
[17] R. Byers, “Solving the algebraic Riccati equation with the matrix sign function,” Linear Algebra Appl., vol. 85, pp. 267–279, 1987.
[18] Oberwolfach model reduction benchmark collection, IMTEK, http://www.imtek.de/simulation/benchmark/.
[19] P. Benner and E. Quintana-Ortí, “Solving stable generalized Lyapunov equations with the matrix sign function,” Numer. Algorithms, vol. 20, no. 1, pp. 75–100, 1999.
]]> [20] P. Benner, P. Ezzatti, E. S. Quintana-Ortí, and A. Remón, “Using hybrid CPU-GPU platforms to accelerate the computation of the matrix sign function,” in Euro-Par 2009, Parallel Processing - Workshops, ser. Lecture Notes in Computer Science, H.-X. Lin, M. Alexander, M. Forsell, A. Knupfer, R. Prodan, L. Sousa, and A. Streit, Eds. Springer-Verlag, 2009, no. 6043, pp. 132–139.[21] P. Strazdins, “A comparison of lookahead and algorithmic blocking techniques for parallel matrix factorization,” Department of Computer Science, The Australian National University, Canberra 0200 ACT, Australia, Tech. Rep. TR-CS-98-07, 1998.
[22] Texas Advanced Computing Center, http://www.tacc.utexas.edu/tacc-software/gotoblas2.
[23] “Open BLAS,” Lab. of Parallel Software and Computational Science, ISCAS, 2013, http://xianyi.github.io/OpenBLAS/.
[24] “The CUDA development kit from SECO,” NVIDIA, 2013, http://www.nvidia.com/object/seco-dev-kit.html.
]]>