











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo

 Permalink
PermalinkIntroducción
La modelización forestal permite simular los efectos de los tratamientos silvícolas y proyectar las consecuencias de una determinada decisión sobre la producción final. Un modelo es una abstracción simplificada de la realidad, en la cual se representan algunas de las propiedades del sistema original, que pasa a ser expresado en términos de ecuaciones matemáticas que lo describen de forma más sencilla (Vanclay, 1994; Sanquetta, 1996). La dinámica forestal se representa mediante ecuaciones que explican de manera cuantitativa las tasas de cambio en crecimiento y densidad del rodal a través del tiempo. Las ecuaciones integradas en un sistema describen las relaciones entre un conjunto de variables bajo el supuesto de simultaneidad (Borders y Bailey, 1986), y presentan una lógica interna de manera de ser fieles a la biología del sistema. La calidad de las estimaciones realizadas está directamente relacionadas con la calidad de la información suministrada. Las características de los ciclos del cultivo forestal hacen de la modelización una de las herramientas más útiles para el sector, por lo cual el desarrollo de modelos para el pronóstico del crecimiento, producción y aprovechamiento es tema central de investigación e innovación del sector forestal (Gadow, Real y Álvarez, 2001).
En el ámbito forestal los modelos de simulación operan a nivel de árboles individuales o a nivel de grupos de árboles o rodales, utilizando como variables predictoras las variables de estado que definen la unidad de modelación: edad, diámetro a la altura del pecho (DAP), diámetro cuadrático medio (Dg), densidad (N), área basal por hectárea (G), calidad o índice de sitio (IS) y cambios de estructura y composición como los generados, por ejemplo, por podas y raleos (Alder, 1980; Costas et al., 2006). Los modelos de mayor difusión en el ámbito forestal para Eucalyptus globulus L. son determinísticos y operan a nivel de rodal, empleando para su ajuste bases de datos empíricas (Tomé et al., 1995; García y Ruiz, 2003; Methol, 2006; Wang y Baker, 2007). Dichos modelos posibilitan la simulación de diferentes escenarios y la toma de decisiones mediante el uso de una estructura de inventarios forestales que facilita su actualización a medida que crece la base de datos. La evolución de un rodal se representa mediante ecuaciones dinámicas o de transición, que explican las tasas de cambio en crecimiento y densidad de la estructura de la masa forestal (Alder, 1980).
Las funciones de transición deben de cumplir una serie de propiedades, entre las que destacan las siguientes: polimorfismo (curvas de diferentes formas, no proporcionales entre sí y asíntota común o diferente), pauta de crecimiento sigmoideo con un punto de inflexión, capacidad de alcanzar una asíntota horizontal a edades avanzadas, respuesta lógica, y ser invariantes con respecto al intervalo de simulación (path invariance) y a la edad de referencia (base age invariance) (Bailey y Clutter, 1974; Cieszewski y Bailey, 2000). Los primeros en formalizar la propiedad de base age invariance (BAI) fueron Bailey y Clutter (1974). En BAI se incluye una estimación de parámetros mediante el uso de una metodología de ajuste que sea también BAI, es decir, que las estimaciones de los parámetros no dependan de un punto arbitrariamente seleccionado como referencia y que permitan el empleo de todos los datos disponibles, en oposición con la metodología clásica base age specific (BAS) (Cieszewski, 2003). Bailey y Clutter (1974), propusieron una metodología para obtener ecuaciones dinámicas con estas características que es conocida en la literatura forestal como algebraic difference approach (ADA). Por su parte Cieszewski y Bailey (2000) propusieron una generalización de la metodología ADA, el método de las ecuaciones de diferencias algebraicas generalizado (GADA: generalized algebraic difference approach).
El objetivo del presente trabajo es desarrollar un modelo dinámico de rodal para E. globulus mediante ecuaciones de transición para área basal, altura media dominante (AMD) y mortalidad. Se utilizó un método invariante respecto a la edad de referencia para estimar los efectos específicos del sitio: el enfoque de las variables dummy (dummy approach) propuesto por Cieszewski, Harrison y Martin (2000), el cual asume que los datos contienen errores de medición y errores aleatorios que deben ser modelados. Las ecuaciones seleccionadas para integrar el modelo se ajustarán con un método adecuado para contemplar su simultaneidad y la posible correlación de los residuales. Junto con la estimación del volumen por hectárea las ecuaciones ajustadas permitirán el empleo del modelo dinámico desarrollado en Sistemas de apoyo a la toma de decisiones (DSS: decision support systems en inglés), para plantaciones de E. globulus en Uruguay.
Materiales y métodos
Datos
Los datos empleados en este estudio corresponden a mediciones de inventario realizadas a 168 parcelas pertenecientes al Instituto Nacional de Investigación Agropecuaria (INIA Uruguay), ubicadas en el sur y sureste del Uruguay.
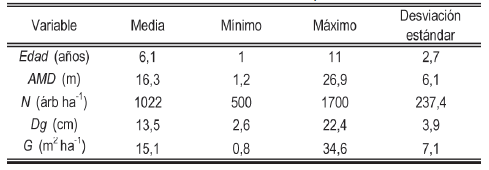
Ajuste de ecuaciones de transición
Las ecuaciones dinámicas empleadas fueron desarrolladas siguiendo dos metodologías clásicas, algebraic difference approach (ADA) y generalized algebraic difference approach (GADA). ADA genera tanto curvas anamórficas (curvas de igual forma y diferentes asíntotas proporcionales entre sí) como polimórficas, siendo su principal limitante que la mayoría de los modelos derivados son anamórficos o polimórficos con asíntota común (Bailey y Clutter, 1974; Cieszewski y Bailey, 2000). GADA posee como principal ventaja la obtención de ecuaciones dinámicas a partir de un modelo de crecimiento base permitiendo que más de un parámetro dependa de las condiciones específicas del sitio forestal, con lo cual las familias de curvas obtenidas son más flexibles (Cieszewski y Bailey, 2000; Cieszewski, Harrison y Martin, 2000; Cieszewski, 2002, 2003). Con esta generalización se obtienen familias de curvas polimórficas y con múltiples asíntotas, que resultan invariantes con respecto la edad de referencia e invariantes al intervalo de simulación (Cieszewski, 2002, 2004).
Se ajustaron 32 ecuaciones ADA y GADA para las variables altura media dominante y área basal por hectárea, derivadas de funciones base existentes en la literatura forestal (Hossfeld, 1882; Schumacher, 1939; Lundqvist, 1957; Richards, 1959; McDill y Amateis, 1992; Amaro et al., 1997; Tomé, Ribeiro y Soares, 2001; Methol, 2001, 2006, 2008; Cieszewski, 2002; Diéguez et al., 2005; Barrio et al., 2006). Las ecuaciones seleccionadas para cada variable de estado integraron un sistema para su ajuste simultáneo, aplicando el método adecuado según las relaciones analíticas que se presentaron.
En los Cuadros 2 y 3 se presenta las ecuaciones ADA de transición polimórficas y anamórficas respectivamente.


El Cuadro 4 presenta las ecuaciones en GADA y las ecuaciones base de donde derivan. Para modelar la evolución del número de árboles por hectárea se evaluaron ocho ecuaciones presentadas en el Cuadro 5.


Estimación de parámetros
Cieszewski (2003), trabajando con enfoques BAS y BAI, encontró que BAS presenta un ajuste de menor calidad, con los residuos mal distribuidos, mientras BAI proporciona mejoras en los residuos (magnitud, homogeneidad y distribución), así como en los demás estadísticos de ajuste, en las estimaciones y en sus errores estándar. El supuesto detrás de los métodos de estimación BAI siguiendo a Cieszewski (2003), es que las mediciones de datos siempre contienen errores de medición y ambientales que deben ser modelados. Los errores de medición y errores de muestreo de la variable de respuesta se consideran como fuentes de errores que afectan las estimaciones de los parámetros. Los valores de las variables de estado inicial medidos en campo están sujetos a dichos errores. Así, al ajustar una ecuación dinámica se asume que dicha variable no se ve afectada por este error cuando está a la derecha de la igualdad pero sí cuando está en la parte izquierda de la misma lo que planta una inconsistencia.
En estas condiciones las técnicas de estimación de parámetros aplicadas a modelos lineales y no lineales determinan estimaciones sesgadas (Myers, 1986). No tener en cuenta estos errores de registro provoca la aparición de sesgo en los parámetros estimados y por lo tanto en la predicción del modelo (Goelz y Burk, 1996). Diversos autores proponen distintas metodologías para solucionar este problema (Tait, Cieszewski y Bella, 1988; Gregoire y Schabenberger, 1996; Cieszewski, Harrison y Martin, 2000). El método basado en el empleo de variables dummy, en el cual los valores de la variable de estado (lado derecho de la ecuación), deben ser valores predichos que no pueden ser conocidos hasta que los parámetros hayan sido estimados, fue desarrollado por Cieszewski, Harrison y Martin (2000). En esta metodología los valores iniciales de la ecuación dinámica son los mismos para todos los datos de una unidad de muestreo. El valor de la variable de estado correspondiente a la edad inicial para cada unidad de muestro se estima simultáneamente con el resto de los parámetros globales de la ecuación dinámica, así, las curvas se ajustan a las tendencias individuales de los datos originales. Para aplicar este método es necesario contar con al menos dos mediciones en el tiempo por parcela, y el número de unidades de muestreo debe ser mayor que el número de parámetros globales de la ecuación dinámica.
La precisión de las predicciones del modelo y las estimaciones de los parámetros dependen tanto del modelo como de la estructura de la variable de estado (lado derecho de la ecuación), deben ser valores predichos que no pueden ser conocidos hasta que los parámetros hayan sido estimados, fue desarrollado por Cieszewski, Harrison y Martin (2000). En esta metodología los valores iniciales de la ecuación dinámica son los mismos para todos los datos de una unidad de muestreo. El valor de la variable de estado correspondiente a la edad inicial para cada unidad de muestro se estima simultáneamente con el resto de los parámetros globales de la ecuación dinámica, así, las curvas se ajustan a las tendencias individuales de los datos originales. Para aplicar este método es necesario contar con al menos dos mediciones en el tiempo por parcela, y el número de unidades de muestreo debe ser mayor que el número de parámetros globales de la ecuación dinámica. La precisión de las predicciones del modelo y las estimaciones de los parámetros dependen tanto del modelo como de la estructura de datos utilizada (Borders et al., 1987; Goelz y Burk, 1992; Cao, 1993; Bailey y Cieszewski, 2000; Strub y Cieszewski, 2006). En la literatura se citan diferentes opciones para la estructura de datos (Borders et al., 1987; Huang, 1997), las seis más empleadas son: I) el intervalo ascendente más largo, II) el intervalo más largo, III) todos los intervalos ascendentes y no superpuestos, IV) intervalos sin superposición, V) todos los posibles intervalos ascendentes, y VI) todos los intervalos posibles (TIP); todas con carácter BAS (Cieszewski, 2003). De estas alternativas Goelz y Burk (1992) y Huang (2002) indicaron que TIP genera modelos con un mejor rendimiento predictivo, siendo los resultados más estables y consistentes.
Sistemas de ecuaciones
Los modelos dinámicos están integrados por varios submodelos de crecimiento y producción, uno para cada variable de estado, formando un sistema de ecuaciones interdependientes que simulan los procesos subyacentes a la biología del rodal. Cada ecuación del sistema describe una relación específica entre las variables que lo integran. Buckman (1962) y Clutter (1963) fueron los primeros investigadores en reconocer e identificar las relaciones matemáticas entre las funciones de crecimiento y producción. La interdependencia es una característica inherente al sistema que debe tenerse en cuenta al momento de la estimación y del uso del modelo como un sistema. Existen varios ejemplos de metodologías para la estimación de variables involucradas en funciones de predicción que no contemplan las interrelaciones existentes entre las variables que integran el sistema (Tomé, Falçao y Amaro, 1997; Zunino y Ferrando, 1997), siendo los parámetros de cada ecuación estimados separadamente. Un método de ajuste adecuado de ecuaciones de crecimiento y rendimiento debe tener en cuenta todas las interdependencias y la existencia de correlación contemporánea entre las variables, el clásico ordinary least squares (OLS) no resulta adecuado ya que no es un método multivariante. Gujarati (1996) menciona que OLS da estimadores eficientes y consistentes para una sola ecuación, pero no ocurre lo mismo para un sistema de ecuaciones, en este caso es necesario emplear un método de estimación multietapa. Diversos autores como Murphy y Beltz (1981), Murphy (1983), Amateis y McDill (1989), Burkhart (1986), Reed (1987), LeMay (1988), Borders (1989), entre otros, han utilizado métodos que generalizan el clásico OLS (métodos instrumentales por ejemplo) para estimar los parámetros estructurales de las ecuaciones que integran sistemas. Un método de ajuste adecuado debe tener en cuenta todas las interdependencias y correlaciones existentes entre las variables involucradas en un modelo de crecimiento y producción. El clásico OLS no es adecuado para ajustar ecuaciones de crecimiento y producción juntas, dado que se pueden originar estimaciones sesgadas debido a la dependencia entre las variables endógenas y el error estocástico (correlación). En el sistema es probable que los residuales de las ecuaciones estén correlacionados por estar asociados a atributos de la misma unidad de medición (crecimiento de los árboles, edades de las parcelas), existiendo correlaciones contemporáneas en la matriz de varianza y covarianza
El uso de ajuste simultáneo de ecuaciones en el ámbito forestal es escaso, remontándose a trabajos de Furnival y Wilson (1971), siendo mayoritariamente utilizado en ecuaciones aditivas de biomasa (Balboa, 2005). Según Pyndyck y Rubinfeld (1981) existen tres tipos de sistemas de ecuaciones:
1. Sistemas de ecuaciones aparentemente no relacionadas.
2. Sistemas de ecuaciones simultáneas.
3. Sistemas de ecuaciones recursivas.
Borders (1989), Somers y Farrar (1991), entre otros han demostrado que ciertas técnicas procedentes del campo de la econometría son útiles en la estimación de sistemas de ecuaciones interdependientes. Son ejemplos de estas técnicas seemingly unrelated regression (SUR) (Zellner, 1962), two stage least squares (2SLS) (Theil, 1953), three-stage least squares (3SLS) (Zellner y Theil, 1962) y full information of maximum likelihood (FIML) (Hausman, 1975). SUR o mínimos cuadrados generalizados conjuntos es una generalización de OLS para sistemas de ecuaciones en los cuales existe correlación, OLS asume que los términos del error no están correlacionados contemporáneamente y tienen la misma varianza en cada ecuación. OLS y SUR son métodos que asumen que todas las variables regresoras son variables independientes, pero SUR toma en cuenta la correlación entre los errores de las diferentes ecuaciones para mejorar la eficiencia de las estimaciones. Esta metodología se inicia estimando la matriz de covarianza de los errores entre las ecuaciones del sistema; en primer lugar se ajustan todas las ecuaciones empleando OLS, y así se determinan los residuos que se usan a continuación para estimar la matriz de covarianza. Seguido, se realiza la estimación SUR. Se ha demostrado que SUR proporciona una ganancia en la eficiencia de la estimación de los parámetros cuando los términos del error en un sistema de ecuaciones están correlacionados (Zellner, 1962; Judge et al., 1988; Rose y Lynch, 2001).
El método 2SLS en un primer paso remplaza las variables endógenas del sistema con su valor predicho obtenido por regresión lineal múltiple empleando todas las variables exógenas del sistema como variables independientes. En un segundo paso las ecuaciones con las nuevas variables son ajustadas con OLS clásico. En esta metodología se asume que esas variables endógenas predichas que aparecen en el lado derecho del sistema no están correlacionadas con los componentes del error de las variables endógenas del lado izquierdo. Los parámetros estimados por esta metodología son sesgados pero consistentes. El método 3SLS va un paso más adelante y combina el método 2SLS con el método SUR para tener en cuenta la correlación entre los componentes del error de varias ecuaciones. FIML es un método que a diferencia de 2SLS y 3SLS, que usan en la estimación de las variables endógenas sólo una proporción del modelo (variables exógenas), emplea todo el modelo en la estimación, aunque en ocasiones resulta complicado obtener la convergencia en dicha estimación.
Estimación de volumen por hectárea
Las ecuaciones de volumen evaluadas fueron modelos predictivos que emplean como predictoras las variables de estado (AMD, G y N) y varias relaciones y transformaciones de las mismas (logarítmicas, exponenciales, inversos, etc.). Para la evaluación de la homocedasticidad se realizaron chequeos gráficos de residuales crudos y de Pearson frente a los valores predichos de los modelos seleccionados. La heterocedasticidad influye en el modelo ya que si ocurre los estimadores son consistentes pero no son eficientes volviendo las fórmulas de las varianzas de los estimadores de los parámetros incorrectas lo cual invalida las pruebas de significación. Las metodologías utilizadas para corregir la falta de homogeneidad de varianza son la transformación de variables implicadas en las ecuaciones o el análisis ponderado (Cunia, 1986; Parresol, 1999, 2001).
Neter et al. (1998) sugieren emplear una función potencia en el análisis ponderado de la siguiente forma:
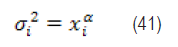
Para estimar el valor α (término de potencia), siguiendo lo propuesto en Parresol (1999), se usaron los errores obtenidos con el modelo sin ponderar (êi) como variable dependiente en el modelo potencial de la varianza del error:
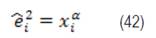
O su forma linealizada:
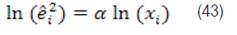
donde:
êi , es el residuo sin ponderar, xi nueva variable, ln logaritmo natural y α parámetro a estimar.
Calidad de ajuste
La selección de los modelos se basó en el análisis de su capacidad de ajuste y su capacidad predictiva, empleando métodos analíticos y métodos gráficos. Los estadísticos empleados para comparar calidad de ajuste tienen su base en el cálculo de los residuos (Clutter et al., 1983; Prodan et al., 1997; Castedo y Álvarez, 2000): a) el sesgo ( E ) evalúa la desviación de la predicción del modelo respecto de los valores observados; b) la raíz del error medio cuadrático (REMC) analiza la precisión de las estimaciones (Newnham, 1992); c) el coeficiente de determinación ajustado ( 𝑅 𝑎𝑗 2 ), representa la fracción de la variación total en los valores de la variable dependiente que es explicada por el modelo, teniendo en cuenta el número total de parámetros a estimar y el número de observaciones; por último d) el criterio de información de Akaike (AIC). Las fórmulas de cálculo son:
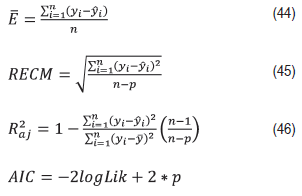
donde:
yi representa los valores observados, y i son los valores predichos, 𝑦 es el valor promedio de la variable dependiente, n es el número de observaciones, p es el número de parámetros del modelo y logLik es el logaritmo de la máxima verosimilitud. Así, según estos estadísticos un modelo será mejor que otro si presenta un menor valor de 𝐸 , RECM y AIC y un mayor valor del 𝑅 𝑎𝑗 2 .
El análisis gráfico de los residuales, permitió detectar fácilmente errores o comportamientos anómalos (Soares et al., 1995; Gadow, Real y Álvarez, 2001; Huang, 2002). Se construyeron curvas de índice de sitio para evaluar el comportamiento lógico de las predicciones frente a la evolución real de las variables.
Capacidad predictiva
El proceso de validación es utilizado para corroborar si la bondad del ajuste refleja también la calidad de las predicciones (Huang, 2002), ya que la calidad de este no refleja necesariamente su capacidad predictiva, lo cual influye en la selección del mejor modelo (Vanclay y Skovsgaard, 1997; Kozak y Kozak, 2003). Las metodologías de validación más usadas son: validación con división aleatoria de datos (split validation) y validación cruzada (cross validation). La primera metodología consiste en probar la capacidad predictiva del modelo en un conjunto de datos independiente del utilizado para su ajuste. La cross validation se realiza con los mismos datos que el ajuste (Myers, 1986) y consiste en el cálculo de los residuos eliminados, es decir en el cálculo de los residuos de la i-ésima observación empleando los parámetros estimados al ajustar el modelo con todos los datos excepto la i-ésima observación. Esta técnica es similar a la split validation, en la cual se parte de un set de datos iniciales y se obtienen dos subconjuntos, salvo que en ella la proporción de los dos conjuntos se mantiene constante. Los datos de validación tienen una observación y el resto de datos se usan para el ajuste (Huang, 2002). El uso de cross validation en el ámbito forestal es una práctica común (Tomé, Ribeiro y Soares, 2001; López et al., 2003; Soares y Tomé, 2002).
La suma de cuadrados de los residuos eliminados se denomina PRESS (predicted residual sum of squares) y se utilizó para calcular los criterios de selección: el sesgo, la raíz del error cuadrático medio (de manera indicada anteriormente por las fórmulas empleadas en el ajuste), y la eficiencia del modelo ajustada (EFaj), cuyas formas de cálculo se presentan a continuación:
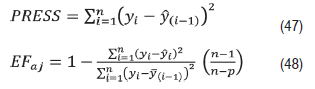
yi representa los valores observados, 𝑦 𝑖 son los valores predichos, 𝑦 (𝑖−1) es el valor promedio de la variable dependiente sin la i-ésima observación, n es el número de observaciones y p los parámetros estimados. La eficiencia del modelo representa la proporción de variabilidad observada en los datos originales que es explicada por el modelo, variando entre 0 (sin ajuste) y 1 (ajuste perfecto) (Vanclay y Skovsgaard, 1997), siendo equivalente al coeficiente de determinación de la fase de ajuste.
Resultados y discusión
La bondad de ajuste de los modelos se evaluó a través de estadísticos numéricos ( 𝐸 , RECM, 𝑅 𝑎𝑗 2 , AIC) con los cuales se confeccionaron rankings de posición y del gráfico de los residuos, analizando las trayectorias predichas para comprobar si son biológicamente adecuados para los datos utilizados (Goelz y Burk, 1992; 1996; Sharma et al., 2011). Finalmente se verificó su calidad predictiva mediante cross validation.
De la base de ecuaciones disponibles (32 para AMD y G, y 8 para Población), se seleccionaron aquellas que obtuvieron los tres primeros lugares en el ranking final (valores más bajos de RECM y AIC y un mayor valor del 𝑅 𝑎𝑗 2 ), las cuales pasaron a la evaluación gráfica en el mismo orden que entraron al ranking.
Se empleó el módulo Proc MODEL del programa estadístico SAS 9.2 para el ajuste y evaluación de los modelos. Para el arreglo de datos y trayectorias se confeccionaron macros mediante Proc SQL (SAS 9.2).
Altura media dominante
Para cuantificar la ganancia en calidad de ajuste se probaron dos estructuras de datos: todos los intervalos posibles (TIP) (Huang, 1997) y variables dummy (Cieszewski, 2002) mediante programación utilizando Proc SQL (SAS 9.2). Para ambas estructuras la ecuación [26] se ubica en el primer lugar del ranking total, y presenta un comportamiento gráfico adecuado. El Cuadro 6 presenta las estadísticas de ajuste para la ecuación [26]; los valores de los estimadores y sus errores estándar se presentan en el Cuadro 7.
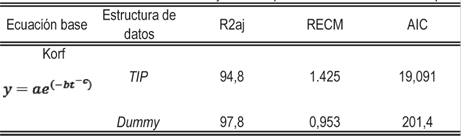
Cuadro 6: Estadísticas de bondad de ajuste total para el modelo seleccionado para AMD, según estructura de datos utilizada.

Se aprecian diferencias en las estadísticas de ajuste para ambas estructuras de datos. Cuando se usan variables dummy se obtienen mayores valores de y menores valores en el RCM.
Las dos estructuras de datos utilizadas brindan diferentes estimaciones de los parámetros y de sus respectivos errores estándar, resultados coincidentes con los obtenidos por Ni y Zhang (2007) quienes compararon diversas estructuras de datos. En la estructura TIP, al ordenar los datos en los correspondientes intervalos de años, el número de observaciones se incrementa artificialmente a un total de 5382. Esto tiene como resultado que los errores estándar de las estimaciones de los parámetros sean subestimados, resultando inapropiados para la prueba de hipótesis o inferencia estadística (Ni y Zhang, 2007).
En las Figuras 1 y 2 se presentan las distribuciones de los valores residuales frente a los predichos y las trayectorias generadas por la ecuación seleccionada (para TIP y dummy respectivamente).
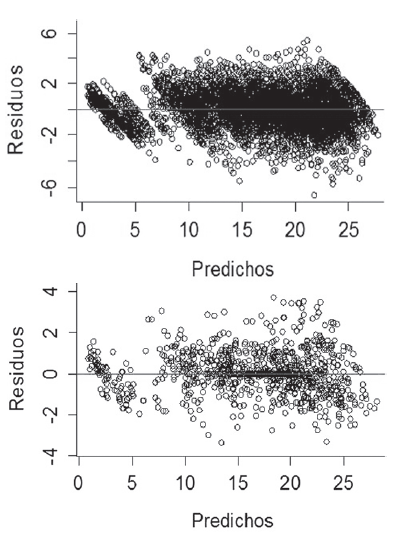
Figura 1: Dispersión de los valores residuales versus los valores predichos generados por la ecuación 26 para AMD . Superio: estructura de datos TIP. Inferior: estructura de datos dummy.
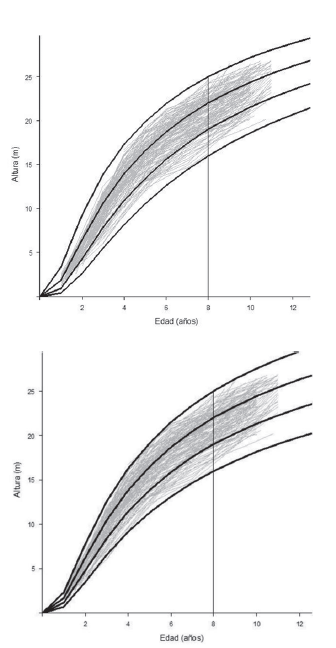
Figura 2: Curvas para índices de sitio de 16, 19, 22 y 25 m a los 8 años (edad de referencia), producidas por el modelo de Korf (26) en GADA (líneas en negro) y las trayectorias reales de AMD (líneas en gris). Superior: estructura de datos TIP. Inferior: estructura de datos dummy.
Dada la ganancia en precisión (Cuadros 6 y 7) y el mejor ajuste de las curvas de sitio, generadas para AMD en la estructura dummy, para las variables de estado restantes (área basal y población) no se utilizó TIP.
Son escasos los trabajos sobre modelos dinámicos para E. globulus en Uruguay. Methol (2006) trabajando con esta especie y con una estructura de datos de intervalos ascendentes (Huang, 1997) identifica el modelo de Schumacher (1939) en su versión polimórfica (ADA) como el de mejor ajuste para la evolución de AMD, mientras que en este estudio dicho modelo obtuvo el segundo lugar en el ranking total para TIP. Amaro et al. (1997) y García y Ruiz (2003) señalan el modelo de Bertalanffy-Richards (Richards, 1959) en su versión polimórfica como el más utilizado para modelar AMD. Por su parte, Inions (1992), Wong et al. (2000) y Strandgard et al. (2005), seleccionaron la versión polimórfica (ADA) del modelo base de Bertalanffy-Richards en Australia para esta especie.
No hay registros de trabajos anteriores que utilicen la versión GADA de Korf (1939) para modelar AMD en especies de Eucalyptus. Por su parte Vargas et al. (2013) y Sharma et al. (2011) trabajado con Pinus pseudostrobus y Pinus sylvestris respectivamente, señalan que esta ecuación presenta buenos estadísticos de ajuste y tendencia aceptables para AMD. Castedo et al. (2007) ajustaron esta ecuación a la evolución del área basal, empelando variables dummy para Pinus radiata en Galicia.
Área basal por hectárea
Para el ajuste de esta variable se empleó únicamente la metodología de variables dummy. Son pocos los registros sobre el empleo de esta metodología para el modelado de área basal (Castedo, Diéguez y Álvarez, 2007; Castedo et al., 2007). Las ecuaciones que obtuvieron los primeros tres lugares en los rankings de estadísticos fueron: Levakovic III (Zeide, 1993), Schumacher (1939) y Bertalanffy (1957), todos ellos en su versión anamórfica. Siendo el modelo base de Levakovic III el de mejor ajuste para área basal por hectárea y el de mejor comportamiento gráfico.
En las Figuras 3 y 4 se observa la distribución de los residuos y las curvas desarrolladas por el modelo junto a las trayectorias de los datos reales.
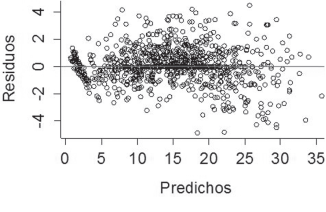
Figura 3: Dispersión de los residuos frente a los valores predichos generados por el modelo anamórfico de Levakovic III, para el ajuste en área basal empleando variables dummy.
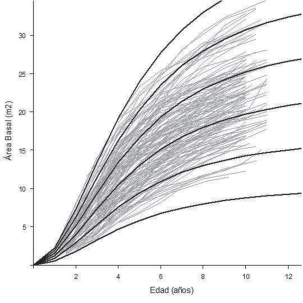
Figura 4: Curvas de crecimiento en área basal de 8, 13, 18, 23, 28, 33 m2ha-1 a la edad de referencia (líneas en negro) y trayectorias de los valores observados en el tiempo (líneas en gris).
Methol (2006), identifica la ecuación propuesta por Draper y Smith (1981), con base en el modelo Monomolecular en versión polimórfica como la de mejor ajuste para esta variable para E. globulus en Uruguay, por su parte, Cordero, Velilla y Aedo (2004) ajustan el mode lo de Clutter (1963) para valores por hectárea de área basal de E. globulus en Chile.
Número de árboles por hectárea
En el ajuste de la densidad de población (evolución del número de árboles por hectárea) se utilizaron datos de parcelas con y sin mortalidad empleando variables dummy. Las ecuaciones seleccionadas para su evaluación gráfica fueron Pienaar y Shiver (1981), Methol (2008) y Tomé, Falçao y Amaro (1997); las cuales lograron las tres primeras posiciones en el ranking final.
El modelo que obtuvo el primer lugar en el ranking total, Pienaar y Shiver (1981), demostró un comportamiento gráfico adecuado. En las Figuras 5 y 6 se observan la distribución de los residuos y las curvas desarrolladas por el modelo seleccionado junto a las trayectorias de las poblaciones reales.
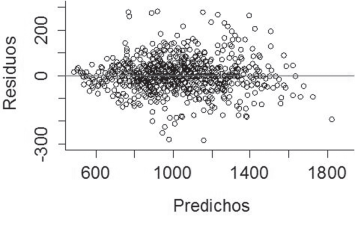
Figura 5: Dispersión de los residuos frente a predichos generados por el modelo Pienaar y Shiver, para el ajuste de densidad empleando variables dummy.
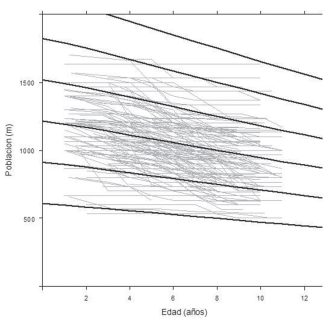
Figura 6: Curvas de evolución del número de árboles por hectárea (líneas en negro) y trayectorias reales (líneas en gris) para 750, 1000, 1250, 1500, 1750 árboles ha-1 a los 8 años (edad de referencia).
Methol (2006) ajustó la ecuación propuesta por Clutter y Jones (1980), para esta especie en Uruguay, por su parte Álvarez et al. (2004) logran buenos estadísticos de ajuste para el modelo de Pienaar trabajando con P. radiata en Galicia al igual que Diéguez et al. (2005) al trabajar con P. sylvestris.
En la evaluación gráfica los residuos AMD y N, no mostraron patrones que indicaran heterocedasticidad, en el caso de AB si bien se visualiza una leve tendencia no presentó problemas.
Ajuste simultáneo
En este trabajo se empleó la metodología de regresión aparentemente no relacionada (seemingly unrelated regression, SUR) ya que se evidenció la presencia de correlación entre residuales (Cuadro 8) de las ecuaciones individuales. El ajuste simultáneo del sistema de ecuaciones formado por el conjunto de modelos seleccionados anteriormente para cada una de las variables de estado se hizo con Proc MODEL del programa estadístico SAS 9.2.En el Cuadro 9 se aprecian los estadísticos de calidad y precisión del ajuste SUR.
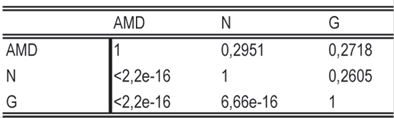

Para las tres variables en estudio (AMD, G y N), SUR generó estadísticos similares que Ordinary least squares (OLS), y no se registró variación de magnitud significativa en la precisión o en la calidad de la estimación. La ganancia en eficiencia es alta si los errores entre las diferentes ecuaciones están correlacionados (Judge et al., 1988), en estos casos SUR podría incrementar la precisión de las predicciones del modelo. La precisión alcanzada en el sistema concuerda con lo reportado por Galán, de los Santos y Valdez (2008), quienes trabajando con Cedrela odorata L. y Tabebuia donnell-smithii R. lograron una precisión de 89,6 a 94,8 % con ajuste SUR para altura dominante y área basal respectivamente. Por su parte Amaro et al. (1997) usaron datos de Eucalyptus globulus para construir un modelo de rodal para altura media dominante y área basal empleando SUR para evitar la correlación entre los residuales de los modelos. Sullivan y Clutter (1972), utilizando datos de índice de sitio, edades iniciales y finales así como valores de área basal, modelaron dicha interdependencia mediante un sistema de ecuaciones de crecimiento y producción empleando el método de OLS. Este enfoque produjo estimadores ineficientes ya que OLS no tiene en cuenta las interrelaciones entre las ecuaciones del sistema (Borders y Bailey, 1986; Borders, 1989). El empleo de métodos alternativos soluciona este inconveniente. Van Deusen (1988) sugiere que si el sistema de ecuaciones cae en el domino de regresión SUR, la estimación de los parámetros estructurales será consistente y asintóticamente eficiente.
Gallant (1975), Murphy (1983) y Borders (1989) emplearon un sistema de ecuaciones no lineales para ajustar volumen actual y futuro, así como densidades de rodal, estimando los parámetros mediante SUR. Por su parte, Borders y Bailey (1986) usaron 2SLS y 3SLS para resolver un sistema de cinco ecuaciones y comparar sus resultados con las estimaciones obtenidas para las mismas empelando OLS, mostrando que 3SLS explica un poco menos de la variación observada que OLS, pero aumenta la ganancia en consistencia de los estimadores.
El Cuadro 10 muestra los valores estimados de los parámetros y sus correspondientes errores estándar para ambos métodos de ajuste (OLS y SUR).
Estimación de volumen por hectárea
Las ecuaciones de volumen ensayadas son modelos de predicción, así, el volumen estimado se predice con los valores proyectados de las variables de estado (AMD, G y N) para una edad determinada. Se evaluaron una serie de relaciones y transformaciones de las variables mencionadas (logarítmicas, exponenciales, inversos y varias combinaciones de las mismas), utilizando el método Stepwise del procedimiento para regresiones (Proc REG) del SAS 9.2.
La regresión seleccionada fue:
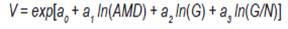
donde:
ln es logaritmo natural, V es el volumen total por hectárea; AMD es altura media dominante; G, área basal por hectárea;N, número de árboles en pie y, a0, a1, a2, a3, parámetros a estimar. Al igual que la ecuación ajustada por Methol (2006) para parcelas de E. globulus, la estimación del volumen se efectuó mediante una ecuación exponencial que incluye la transformación ln del área basal, el número de árboles y la altura media dominante a la edad de interés como variables explicativas. Para detectar el desvío de la homocedasticidad de los residuales se realizaron gráficas de residuales crudos y de Pearson frente a los valores predichos de los modelos seleccionados.
Para corregir la heterocedasticidad presente se ajustó la ecuación [43], empleado una función potencia del área basal de la parcela. La función xi y el parámetro α se estimaron mediante el Proc REG (SAS 9.2), siguiendo la metodología descripta anteriormente (Parresol, 2001). La ponderación de las observaciones se realizó utilizando la siguiente ecuación:
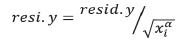
disponible en SAS Proc MODEL del programa estadístico SAS 9.2, siendo y la variable dependiente del modelo.
Validación
Una vez seleccionados y ajustados los modelos se procedió a su validación (cross validation). En el Cuadro 11 se presentan los valores del sesgo, la raíz del error cuadrático medio y la eficiencia ajustada del modelo para cada variable de estado.
Los valores observados no difieren en gran magnitud de los obtenidos en el ajuste de cada modelo, como se presentaron en el capítulo correspondiente a cada variable de estado, siendo de muy buena calidad tanto en ajuste como en precisión.

Conclusiones
Los sub-modelos seleccionados para integrar el modelo dinámico de crecimiento y producción para plantaciones de Eucalyptus globulus con destino pasta de celulosa, han sido ajustados siguiendo metodologías invariantes respecto a la edad de referencia (ADA, GADA y variables dummy). Proporcionan curvas con mayor flexibilidad y representan con mayor fidelidad las trayectorias reales, levantando algunas de las limitantes de los modelos utilizados tradicionalmente.
Se seleccionó el modelo propuesto por Korf modificado por Cieszewski (2004) para la altura media dominante en su versión GADA, que produce curvas polimórficas de asíntotas variables, con un 𝑅 𝑎𝑗 2 de 97,8 % y RCEM de 0,953 m. Su expresión es:

Para área basal por hectárea el modelo seleccionado fue el de Levakovic en su versión ADA anamórfica, con un R 2 af de 97,4 % y RCEM de 1,217 m2. Su expresión es la siguiente:
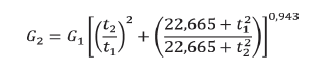
El modelo de Pieneer y Shiver (1981) fue el seleccionado para la evolución de la población, con un 𝑅 𝑎𝑗 2 de 92,6 % y RCEM de 63,69 árboles.
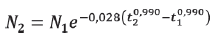
El ajuste simultáneo (SUR) realizado debido la presencia de correlación entre los residuales de las ecuaciones seleccionadas no reveló cambios en la significancia de los parámetros ajustados.
El empleo de la función de estimación de volumen permite la utilización de los modelos seleccionados en sistemas de apoyo a la gestión. La ecuación de predicción para el volumen por hectárea ajustada es:
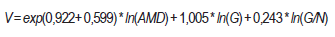
donde
AMD = altura media dominante, G = área basal y N = número de árboles
La base de datos utilizada comprendía parcelas de entre uno y 11 años, sobrepasando la edad de turno (ocho años).

