











 Portugués (pdf)
Portugués (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo

 Permalink
Permalink
1. Introdução
Em português, como em qualquer outra língua, existem estruturas linguísticas regulares ou fixas que constituem expressões cujo significado depende da observação de características segmentais e suprassegmentais de seus constituintes.
Os agrupamentos numéricos, utilizados para nomear entidades, distinguindo-as entre si (Wiese 2003), são exemplos dessas estruturas regulares. O presente trabalho apresenta uma descrição da estrutura e das características entoacionais de um agrupamento numérico muito produtivo no português brasileiro (PB): aquele associado ao código de endereçamento postal (CEP).
Com o avanço da tecnologia, tem-se tornado cada vez mais frequente o uso de sistemas automatizados de síntese e reconhecimento de fala nos mais diversos âmbitos de aplicação. Assim, por exemplo, já há uma quantidade significativa de serviços que faz uso de informações derivadas de conjuntos numéricos conectados para os mais variados fins: ativação de cartões de crédito, informações bancárias, consultas a listas telefônicas e marcações de reservas são alguns dos exemplos mais comuns de tal aplicação. Em muitos casos, entretanto, a performance desses sistemas tem sido considerada sofrível, ora por não processarem corretamente a fala espontânea (no caso de sistemas de reconhecimento de fala), ora por não oferecerem uma produção próxima à fala natural (no caso dos sistemas de síntese de fala).
É ainda muito comum, por exemplo, que usuários de linhas telefônicas se queixem dos sistemas automatizados com que em geral têm de interagir ao telefone, uma vez que simplesmente não reconhecem aquilo que falam. Nessas situações, escutam, em geral, um indefectível e frustrante feedback, do tipo: “não entendi”. As queixas também se referem ao modo como certos agrupamentos numéricos são enunciados por sistemas de síntese de fala. A maneira como esses sistemas agrupam números e a prosódia que utilizam para enunciá-los nesses casos em nada se assemelham à sua enunciação natural. Isso tem um impacto significativo em termos de compreensão desses constituintes, o que é evidentemente algo indesejável no que concerne ao que se espera de sistemas automatizados de síntese de fala.
Esses problemas devem-se em parte ao fato de serem tais sistemas o mais das vezes baseados em dados controlados e/ou resultantes de análises impressionistas e não em dados resultantes de análises de dados de fala natural e espontânea. Deriva daí a necessidade premente de informações que visem ao aperfeiçoamento dos sistemas computacionais automáticos ora em uso.
Avanços nessa área têm sido obtidos em decorrência da descrição da estrutura prosódica de números naturais nas mais diversas línguas, tais como o inglês (Rahim et al. 2001), o alemão (Baumann e Trouvain 2001, Creer 2002), o espanhol (López et al. 1998), o francês (Mokbel et al. 1997), o japonês (Amino e Osanai 2011), o húngaro (Olaszi 2000), o chinês (Wang e Seneff 1998) e o português europeu (Rodrigues 2001). Até o momento, poucos são os trabalhos sobre o português do Brasil que descrevem, de forma sistemática e abrangente, as várias características acústicas da organização de números naturais em estruturas pré-estabelecidas (Almeida 2017, Oliveira Jr e Silva 2017, Musiliyu 2014).
O presente estudo visa a contribuir nesse sentido, apresentando uma descrição da prosódia de agrupamentos numéricos em uma estrutura fixa (o código de endereçamento postal brasileiro), tal como enunciada espontaneamente.
Objetiva-se também, e a partir dos resultados dessa análise, propor um modelo de descrição e geração a ser usado para aprimorar sistema de síntese e reconhecimento de fala para o português do Brasil. O estudo sobre a prosódia de números nominais de CEP integra, dentre outras, questões de estruturação, agrupamento, entoação e constitui uma contribuição para a pesquisa sobre os números falados em geral, que claramente desempenham um importante papel na nossa interação cotidiana.
Para Reed (2011), o primeiro passo em qualquer análise prosódica é a identificação das unidades prosódicas, unidades linguísticas definidas por aspectos suprassegmentais da fala. São fragmentos de fala que constituem uma unidade caracterizada pela presença de fronteiras que os delimitam. Apesar de caracterizadas com base em uma variedade de critérios, a intuição tem papel relevante na identificação das fronteiras que limitam essas unidades. De acordo com Chafe (1994), são as características acústicas primitivas, identificadas intuitivamente, que definem as fronteiras prosódicas que delimitam essas unidades da fala. Além disso, Selkirk (1984, 1986), Nespor e Vogel (2007) e Ladd (2008) destacam a importância da estrutura morfossintática e de informações semântico-pragmáticas na formação das unidades prosódicas e, consequentemente, na identificação de fronteiras prosódicas.
Além da pausa, outros parâmetros prosódicos, como aqueles relacionados à variação de frequência fundamental (f0), fornecem pistas para a demarcação/identificação dessas fronteiras. A seção seguinte aborda os procedimentos e o embasamento teórico adotados na presente investigação.
2. Procedimentos metodológicos
Os dados utilizados no presente estudo são resultantes de uma coleta realizada em áudio, mediante uma pequena entrevista durante a qual os participantes foram solicitados a enunciar informações pessoais, tais como: cor favorita, preferência no esporte, local de residência, números de telefone (fixo e móvel), número de CPF e o CEP de sua residência. Para essa tarefa, os participantes não consultaram seus dados pessoais; eles enunciaram apenas os números que haviam memorizado.
A coleta de dados seguiu critérios técnicos e recomendações de Oliveira Jr (2014). Os registros das gravações foram feitos em formato PCM, não-comprimido (gravados em formato wav), com taxa de amostragem de 96kHz e 32 bits por amostra, utilizando-se um microfone tipo headset DPA Headband 4066 e um gravador digital de flash Marantz PMD661. A adoção de tais medidas garantiu arquivos de áudio de alta qualidade e, consequentemente, condições para análises acústicas acuradas2.
Os arquivos de áudio foram segmentados individualmente no aplicativo computacional Praat (Boersma 2001). Em seguida, realizamos a segmentação e a anotação dos mesmos, também utilizando o Praat e considerando a identificação das unidades prosódicas.
Para tanto, adotamos uma abordagem intuitiva, utilizando a percepção, enquanto falante nativo da língua, para segmentar os agrupamentos numéricos em unidades menores, seguindo autores que utilizaram a mesma abordagem em sentenças não numéricas, tais como Swerts (1997), Donzel (1999), Oliveira Jr (2000), Serra (2009, 2016), dentre outros.
Estudos prévios (Swerts 1997, Mo et al. 2008, Oliveira Jr et al. 2012) comprovaram que: i) a percepção de ouvintes, ainda que não treinados, na identificação de fronteira prosódica, apresenta relação com as pistas fonéticas previstas para essa posição; e ii) quando realizados testes de concordância entre examinadores, treinados ou não, eles concordam de maneira significativa acerca da segmentação de um mesmo enunciado.
Então, no intuito de examinar em que medida a estrutura dos agrupamentos numéricos de CEP é reconhecida por examinadores (especialistas e leigos) aplicamos o teste estatístico Kappa Fleiss, seguindo metodologia semelhante a Mo et al. (2008) e Oliveira Jr et al. (2012). Os resultados do teste Kappa de concordância entre examinadores apontaram para uma concordância significativa quanto à segmentação dos agrupamentos numéricos de CEP, tanto entre examinadores treinados quanto entre não treinados, já que o coeficiente Kappa não apresentou valores abaixo de 0,86. Sendo assim, procedemos à segmentação e anotação dos dados.
A anotação dos dados foi multinível e organizada em camadas no Praat e todos os testes estatísticos foram realizados por meio do software estatístico R (R Core Team 2016). Utilizamos o script Momel/Intsint (Hirst 2007) para realizar a modelagem acústica que estima pontos-alvo de frequência fundamental e, a partir deles, descreve a entoação por meio de um conjunto controlado de símbolos tonais abstratos no intuito de extrair a representação da entoação. Esse script vem sendo utilizado com sucesso em estudos prosódicos para o PB (Celeste 2007, Musiliyu 2014).
Diante dos dados devidamente anotados, a primeira etapa das análises dos agrupamentos consistiu em verificar a distribuição de frequências numérica (quantidade de números enunciados em cada unidade prosódica) e decimal (forma decimal em que os números foram enunciados: em unidade, dezena ou centena) mais recorrente dos enunciados numéricos de CEP. Por se tratar de variáveis categóricas (número de ocorrências), realizamos o teste estatístico do Qui-quadrado (χ2) de Pearson a fim de mostrar se as distribuições mais recorrentes apresentaram diferença estatisticamente significativa entre elas.
Identificadas as distribuições numéricas e decimais mais recorrentes, procedemos à descrição entoacional, separadamente. Mas, os resultados não divergiram, então decidimos que seria suficiente a demonstração de resultados referentes às distribuições numéricas mais abrangentes. Para essa análise, procedemos inicialmente à segmentação dos áudios dos agrupamentos numéricos de CEP, conforme suas unidades prosódicas, utilizando o script PraatSegmentation3 (Ferreira 2016), baseados na camada onde segmentamos e anotamos as unidades prosódicas.
A decisão de realizar essa ressegmentação e obter arquivos de áudio de cada unidade prosódica deveu-se ao fato de que observamos que o script Momel/Intsint (Hirst 2007) gerava uma descrição entoacional mais precisa em trechos de áudio menores. Então, a fim de gerar uma descrição entoacional com uma representação simbólica o mais precisa possível, realizamos a ressegmentação dos áudios em unidades menores (unidades prosódicas) e, utilizamos o script Momel/Intsint (Hirst 2007) nesses arquivos de áudio resultantes.
Após encontrar os padrões de descrição entoacional gerada pelo Momel/Intsint, realizamos ajustes na transcrição entoacional, seguindo orientações de Hirst (2007) e Louw e Barnard (2004). Portanto, os símbolos utilizados foram: M (para o tom médio), U (subida), T (topo), D (descida) e B (base).
Submetemos os mesmos trechos de áudio à análise semi-automática do script ProsodyPro (Xu 2013), objetivando verificar se o padrão encontrado através da anotação do Intsint correspondia à curva representativa do contorno entoacional gerada a partir dos valores de média entre os enunciados de cada unidade prosódica, considerando os dez pontos-alvo de f0 selecionados equidistantemente pelo ProsodyPro. Tal procedimento foi adotado em pesquisas anteriores (Almeida et al. 2013, Musiliyu 2014) também com o objetivo de demonstrar curvas representativas do contorno entoacional.
Todos os valores correspondentes aos correlatos acústicos desses parâmetros analisados foram extraídos a partir do script AnalyseTier (Hirst 2012), utilizado também em estudos prévios (Hoffmann 2011, Franks e Barbosa 2014, Cabedo 2014, dentre outros). E, por se tratar de variáveis quantitativas, utilizamos o teste estatístico de análise da variância (ANOVA) de Fisher, para verificar se houve diferença significativa entre os níveis de análise.
Para obter os valores referentes à análise acústica da frequência fundamental (variação da f0, declínio da f0 e diferença de tom) das unidades prosódicas a partir do AnalyseTier, utilizamos a tira (camada) gerada na etapa da segmentação e anotação dos dados para identificar as unidades prosódicas.
A variação da f0, medida aqui como pitch range, foi utilizada nessa pesquisa como parâmetro para análise da frequência fundamental, uma vez que, de acordo com Bolinger (1972), Pierrehumbert (1980) e Ladd (2008) a variação da f0 é um dos melhores parâmetros para análise da frequência fundamental, cujos valores foram expressos em semitons (relativos a 100 Hz), seguindo estudos anteriores (Swerts 1997, Oliveira Jr 2000, Cumbers 2013, por exemplo).
Ouden (2004) afirma que a literatura oferece pelo menos duas abordagens para medida dopitch range, uma que considera mais apropriada a utilização do pico mais alto do contorno (Liberman e Pierrehumbert 1984) e outra que afirma ser a diferença entre f0 máxima e f0 mínima a medida mais adequada (Ladd 2008).
Diante da falta de consenso na literatura com relação a qual medida seria mais adequada para análises depitch range, decidimos optar por utilizar como medida depitch rangevalores da f0 máxima, na análise de variação da f0 nas unidades prosódicas e no agrupamento numérico como um todo, seguindo abordagem proposta por Liberman e Pierrehumbert (1984), uma vez que ela também foi utilizada posteriormente por outros autores (Swerts 1997, Oliveira Jr 2000). Além disso, Ouden (2004), ao comparar ambas as medidas, conclui que o valor do pico mais alto consiste em medida mais apropriada depitch rangede toda a unidade prosódica.
A frequência fundamental também foi analisada no que se refere à declinação por meio da diferença da f0 máxima entre a primeira sílaba tônica (PST) e a última sílaba tônica (UST) de cada unidade prosódica, a fim de verificar se houve um declínio da f0 em cada unidade.
Estudos anteriores (Swerts 1997, Oliveira Jr 2000, por exemplo) mostram, ao analisar sentenças declarativas neutras não numéricas, que realmente a frequência fundamental tende a declinar no curso de um enunciado, mas geralmente ela é reiniciada em “junções” (fronteiras) no fluxo da informação. Isso implica que entre unidades prosódicas adjacentes há uma diferença de tom que indica variação da f0 maior no início da unidade seguinte do que no final da anterior.
Por essa razão, também analisamos a diferença de tom, que foi medida a partir de valores de pitch range entre duas unidades adjacentes, seguindo Oliveira Jr (2000). Para isso, comparamos valores da f0 máxima entre a última sílaba tônica de uma unidade prosódica e a primeira sílaba tônica da unidade seguinte.
Dessa forma, pudemos verificar se ocorreu em nossos dados o que Swerts (1997) denominou de descontinuidade melódica, ou seja, quando ocorre um reinício da frequência fundamental (pitch reset), com a subida da f0, a medida que uma nova unidade prosódica é enunciada. Vale destacar que utilizamos os termos pitch range e pitch reset para indicar respectivamente gama da f0 e reinício da f0, mesmo sabendo que o termo “pitch” corresponde ao correlato perceptual da f0, porque as pesquisas em que nos embasamos para a análise utilizam tais termos.
3. Resultados e discussão
Nessa seção, apresentamos análises da distribuição de frequências (numérica e decimal), bem como da distribuição entoacional e da ocorrência de pausas entre as unidades prosódicas dos números de CEP, enunciados de forma espontânea. Além de proceder à análise acústica da f0 (variação de f0, declínio de f0 e diferença de tom). Dos 121 participantes que compuseram o corpus dessa pesquisa, 87 forneceram seus números pessoais de CEP, dos quais 52 foram do sexo feminino.
3.1. Distribuição de frequências
Como um primeiro passo para a análise entoacional dos dados, realizamos o levantamento das estratégias de enunciação utilizadas pelos participantes, tanto no que se refere à distribuição numérica quanto à distribuição decimal, durante a enunciação do CEP. Encontramos 74,71% dos agrupamentos enunciados em uma unidade binária finalizando com duas ternárias.
O resultado do teste χ2, realizado com as duas distribuições numéricas mais recorrentes, já demonstrou haver uma diferença significativa entre tais distribuições (χ2 = 40,333, p < 0,05, df = 1). Portanto, conclui-se que há uma preferência expressiva pela enunciação do CEP numa distribuição numérica que organiza os números em um padrão 2-3-3, como é possível observar na Tabela 1.
Tabela 1: Resultados das estratégias de distribuição numérica
| Agrupamento | Ocorrências | % |
| 2 3 3 | 65 | 74,71 |
| 3 2 3 | 10 | 11,49 |
| 2 2 2 2 | 3 | 3,45 |
| 5 3 | 3 | 3,45 |
| 2 2 1 3 | 2 | 2,30 |
| 1 2 1 1 3 | 1 | 1,15 |
| 1 2 2 3 | 1 | 1,15 |
| 2 2 1 1 1 1 | 1 | 1,15 |
| 2 6 | 1 | 1,15 |
| Total | 87 | 100 |
Esse resultado reforça a ideia de que a disposição gráfica do agrupamento numérico pode interferir na forma como o mesmo é enunciado. Com relação às estratégias de distribuição decimal decorrentes da distribuição numérica mais abrangente, 2-3-3, constatamos que a distribuição decimal: D-UD-C4, foi a mais recorrente (38,46%). A segunda distribuição decimal mais frequente, D-C-UUU, foi enunciada por 12,31% dos participantes ao enunciarem seus números pessoais de CEP, conforme evidenciado no Gráfico 1.
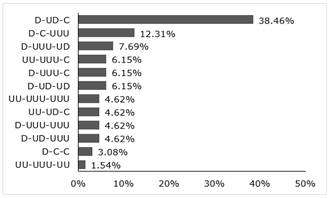
Gráfico 1: Representação gráfica das distribuições decimais da distribuição 2-3-3 enunciadas em unidade (U), dezena (D), centena (C)
No resultado do teste estatístico do Qui-quadrado, já encontramos uma diferença significativa (χ2 = 8,757, p < 0,05, df = 1) entre as duas distribuições decimais mais recorrentes (D-UD-C e D-C-UUU) na enunciação espontânea dos dados pessoais de CEP. Tal resultado evidencia a preferência em enunciar números de CEP por meio da distribuição decimal D-UD-C.
As seções seguintes apresentam resultados das análises das unidades prosódicas resultantes da enunciação espontânea do CEP, no que se refere ao seu contorno entoacional, variação da f0, declínio da f0 e diferença de tom. Conforme salientamos na metodologia, procedemos a essas análises de características prosódicas com dados provenientes da distribuição numérica e das distribuições decimais mais frequentes separadamente. Todavia, os resultados dessas análises individuais não divergiram, o que nos levou a optar por uma análise da distribuição numérica mais abrangente, 2-3-3. Por essa razão, nas seções seguintes, foram analisados 65 agrupamentos numéricos de CEP.
Na seção seguinte, apresentamos resultados referentes às formas de distribuição entoacional da enunciação do número de CEP baseados na anotação dada pelo Momel/Intsint (Hirst 2007) e corroborada pela curva representativa do contorno entoacional gerada a partir do ProsodyPro (Xu 2013).
3.2. Distribuição entoacional
A presente seção evidencia os resultados das análises da descrição entoacional encontrada para os números de CEP, enunciados de forma espontânea, provenientes da distribuição numérica mais recorrente, 2-3-3, a partir da simbologia de anotação do Momel/Intsint, assim como as curvas representativas do contorno entoacional a partir das médias dos valores de f0 gerados pelo ProsodyPro, conforme explicado na metodologia. A Tabela 2 contém resultados das ocorrências (Freq.) de distribuição entoacional (DE) de cada unidade prosódica (UP) de número de CEP enunciado espontaneamente.
Tabela 2: Resultados das estratégias de distribuição entoacional das unidades prosódicas
| UP_01 | UP_02 | UP_03 | ||||
| DE | Freq. | DE | Freq. | DE | Freq. | |
| MDU | 20 | MUDU | 23 | MUDUD | 18 | |
| MUDU | 8 | BUDU | 11 | BUDUD | 7 | |
| TDU | 7 | MDU | 9 | TDUD | 7 | |
| BUDU | 6 | MDUD | 7 | MDU | 6 | |
| MUDUD | 6 | BUDUD | 6 | MDUB | 6 | |
| TDUD | 6 | TDU | 5 | BUD | 4 | |
| BUDUD | 4 | MUDUD | 2 | MUB | 4 | |
| MDUD | 4 | TDUD | 2 | TDU | 4 | |
| MUD | 3 | - | - | BUDU | 3 | |
| TBUDU | 1 | - | - | MUDU | 3 | |
| - | - | - | - | TDB | 2 | |
| - | - | - | - | MDB | 1 | |
| Total | 65 | Total | 65 | Total | 65 | |
Verificamos que a estratégia de distribuição entoacional5 mais frequente para a primeira unidade prosódica, binária, é representada pela simbologia MDU, para a segunda unidade MUDU, enquanto a última unidade apresentou um padrão de contorno entoacional representado pela simbologia mais frequente MUDUD.
Para verificar se tais frequências diferiram de forma significativa da segunda maior frequência em cada unidade prosódica, realizamos o teste estatístico Qui-quadrado cujos resultados estão apresentados na Tabela 3.
Tabela 3: Resultados do teste estatístico para as frequências mais recorrentes de distribuição entoacional por unidade prosódica
| Unidade prosódica | Teste estatístico |
| 01 | (χ2 = 5,14, p < 0,05, df = 1) |
| 02 | (χ2 = 4,23, p < 0,05, df = 1) |
| 03 | (χ2 = 7,56, p < 0,05, df = 2) |
A partir do teste estatístico verificamos que as duas distribuições entoacionais mais recorrentes se mostraram estatisticamente diferentes na primeira e segunda unidades prosódicas. Já na terceira unidade, realizamos o teste estatístico com as três distribuições entoacionais mais frequentes pois a segunda e a terceira distribuições apresentaram o mesmo número de ocorrências, e também constatamos que a frequência da primeira distribuição foi significativamente maior do que as demais.
Os resultados evidenciaram que a primeira unidade prosódica de um número de CEP foi enunciada com um contorno entoacional que pode ser representado pela simbologia MDU (se inicia com um tom médio, seguido de uma descida e terminando com uma subida), a segunda unidade pelo símbolo MUDU, enquanto a última unidade prosódica parece seguir um padrão entoacional MUDUD, encerrando o enunciado do agrupamento numérico de CEP com um tom de descida.
O tom de subida no final das duas primeiras unidades prosódicas indica a presença de uma fronteira prosódica alta, típica de um contorno continuativo para o PB (Cunha 2000, Tenani 2002, Serra 2009, 2016, Frota et al. 2007), e o tom de descida no final da última unidade prosódica é típico de encerramento de enunciado assertivo neutro, conforme achados anteriores para o português brasileiro (Moraes 1998, 2008, Oliveira Jr 2000, Cunha 2000, Frota e Vigário 2000, Tenani 2002, Serra 2009, 2016, Cardoso et al. 2014, Silvestre 2012) e para o holandês (Swerts 1997), por exemplo.
No intuito de ratificar a descrição fonética oferecida pelo Intsint, utilizamos o script ProsodyPro (Xu 2013) para obter valores de f0 cujas médias foram utilizadas na elaboração de gráficos representativos do contorno entoacional para cada unidade prosódica dos números de CEP enunciados de forma espontânea, conforme segue.
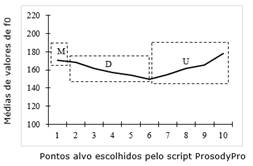
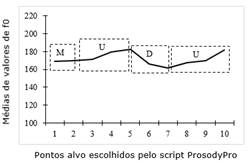
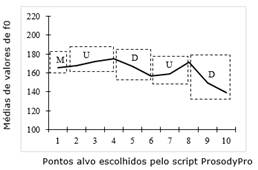
Os dados decorrentes de enunciações espontâneas demonstraram que a anotação do Momel/Intsint considerada padrão para cada unidade prosódica do número de CEP condiz com a correspondente curva representativa do contorno entoacional, gerada a partir de dados originários do ProsodyPro. Tal padrão também corrobora o encontrado por Mussiliyu (2014) ao estudar o contorno entoacional de números telefônicos no PB. A esse respeito, Barbosa e Madureira (2015) acrescentam que a queda do valor de f0 ao final dos enunciados contribui para a percepção de assertividade.
Vale ressaltar que, para obter uma anotação mais precisa do Intsint, a descrição entoacional foi efetuada nos áudios segmentados por unidade prosódica, conforme explicado na metodologia. Tal estratégia justifica o fato de cada unidade prosódica iniciar com o tom médio (M), já que, consoante Hirst (2007, 2012) e Louw e Barnard (2004), os áudios são comumente iniciados com o tom médio na anotação dada pelo script Intsint. Entretanto, ao considerar o agrupamento numérico como um todo, verificamos que há um reinício da f0 a cada nova unidade prosódica enunciada, marcada por uma continuação da subida (U) que marcou o final da unidade anterior, conforme demonstrado no Gráfico 5.

Gráfico 5: Representação gráfica do contorno entoacional padrão das unidades prosódicas (01, 02, 03) do CEP
A seguir, apresentamos resultados sobre a presença/ausência de pausas e acerca de análises acústicas referentes a características prosódicas de variação da f0, declínio da f0 e diferença de tom entre as unidades prosódicas que compõem a enunciação espontânea de números de CEP, seguindo a distribuição numérica mais recorrente, 2-3-3. Tais valores foram extraídos por meio da utilização do script AnalyseTier (Hirst 2012) e ratificam o demonstrado no Gráfico 5.
3.3. Pausa entre as unidades prosódicas
Destarte tratarmos de análise entoacional no presente trabalho, analisamos também a ocorrência de pausas entre as unidades prosódicas, já que em nosso corpus não houve pausas no interior das unidades prosódicas. Tal análise justifica-se por tratar-se de correlatos acústicos duracionais que interferem na entoação. Consideramos pausa como período de silêncio maior do que 150 ms (Kowal et al. 1983). Nos dados de enunciação espontânea dos números de CEP, constatamos um total de 35 pausas, 17 entre a primeira e a segunda unidades prosódicas (Y1) e 18 entre a segunda e a terceira unidades (Y2), o que representa 26,92% das fronteiras encontradas, considerando 2 posições de fronteira para ocorrência de pausas já que 65 participantes enunciaram seus dados pessoais de CEP utilizando uma distribuição numérica 2-3-3.
Ao realizar o teste Qui-quadrado, verificamos que houve uma diferença significativa (χ2 = 27,69, p < 0,05, df = 1) entre o número de ocorrências de pausas (35) e o de não ocorrência de pausas (95). A maioria das pausas ocorreu entre a segunda e a terceira unidades prosódicas (Y2), apesar do teste estatístico não mostrar diferença significativa entre as ocorrências de Y1 e Y2 (χ2 = 0,03, p > 0,05, df = 1). Os resultados apresentados pelos dados de CEP sugerem que a presença de pausas não foi significativa nesses tipos de agrupamentos numéricos.
3.4. Variação da f0 nas unidades prosódicas
Nessa seção, apresentamos resultados a respeito da variação da f0 nas unidades prosódicas da enunciação espontânea dos números de CEP. Assim, conforme explicitamos na metodologia, a variação da f0 é medida aqui como pitch range, tomando como correlato acústico o valor da f0 máxima (Swerts 1997, Oliveira Jr 2000, Ouden 2004). O Gráfico 6 mostra a relação entre os valores da f0 nas unidades prosódicas de CEP.
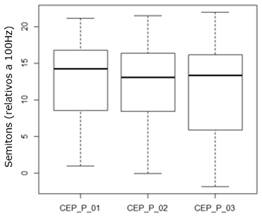
O resultado do teste estatístico ANOVA mostrou que a distribuição dos valores da f0 entre as unidades prosódicas que estão sendo comparadas não apresenta uma diferença estatisticamente significativa, F (2, 192) = 0,714, p > 0,05. Portanto, parece não haver diferenças relevantes de variação da f0 entre as unidades prosódicas na enunciação espontânea de números de CEP. Em seguida, analisamos o declínio da f0 nos números de CEP.
3.5. Declínio da f0 nas unidades prosódicas
O declínio da f0, abordada nessa seção, foi observado por meio da diferença da f0 máxima entre a primeira sílaba tônica (PST) e a última sílaba tônica (UST) de cada unidade prosódica, a fim de verificar se houve um declínio da f0 em cada unidade. A esse respeito, a literatura prévia, que aborda sentenças declarativas neutras não numéricas, afirma que os valores da frequência fundamental máxima no final de uma unidade prosódica tendem a ser mais baixos do que no início da unidade (Swerts 1997, Oliveira Jr 2000).
Isso acontece, de acordo com Ouden (2004), porque os falantes controlam voluntariamente essa declinação, regulando-a de modo a iniciar a sentença com valores altos de f0 no intuito de manter perceptualmente uma declinação saliente. Além disso, Ferreira Netto (2007) apresentou resultados para uma análise da declinação no português do Brasil que converge com esses estudos anteriores, evidenciando que a fala precisa ser pré-programada para ajustar sua duração e sua variação de frequências. Sugere que o falante precisa prever a duração de sua sentença, iniciando com um tom que seja alto o suficiente para que possa ser concluído com um tom baixo.
Percebemos um declínio da f0, no interior de cada unidade prosódica e ao considerar todo o agrupamento numérico do CEP (comparando 01_PST com 03_UST), conforme evidenciado no Gráfico 7.
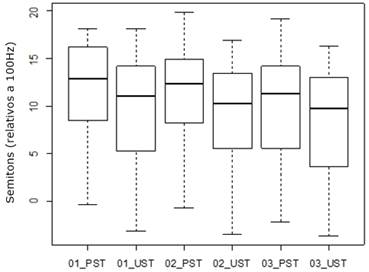
Esse declínio da f0 evidencia que os valores da f0 máxima nas últimas sílabas tônicas são menores do que os das primeiras sílabas tônicas no interior de todas as unidades prosódicas6.
Ao realizar o teste ANOVA verificamos que esse declínio da f0 evidenciado no gráfico é significativo em todas as unidades prosódicas, conforme resultados estatísticos apresentados na Tabela 4.
Tabela 4: Resultados estatísticos relativos ao declínio da f0 no interior das unidades na enunciação do CEP
| Unidades prosódicas | Teste ANOVA |
| 01 | F (1, 128) = 5,45, p < 0,05 |
| 02 | F (1, 128) = 4,35, p < 0,05 |
| 03 | F (1, 128) = 4,07, p < 0,05 |
Considerando todo o agrupamento numérico, verificamos que o declínio da f0 é ainda mais significativo, F (1, 128) = 16,04, p < 0,05. Tais resultados apontam para um comportamento da f0 típico de sentenças declarativas neutras no português brasileiro que apresenta um início marcado pela subida de f0 e um final de sentença marcado pela queda da f0 (Moraes 1998, Oliveira Jr 2000).
Estudos anteriores (Swerts 1997, Oliveira Jr 2000, por exemplo) mostram que realmente a frequência fundamental tende a declinar no curso de um enunciado, mas geralmente ela é reiniciada em “junções” (fronteiras) no fluxo da informação.
Isso implica que entre unidades prosódicas adjacentes há uma diferença de tom que indica variação da f0 maior no início da unidade seguinte do que no final da anterior. Resultados a esse respeito são apresentados na subseção seguinte.
3.6. Diferença de tom entre as unidades prosódicas adjacentes
A diferença de tom foi medida a partir de valores de pitch range entre duas unidades adjacentes, seguindo Oliveira Jr (2000). Para isso, comparamos valores da f0 máxima entre a última sílaba tônica de uma unidade e a primeira sílaba tônica da unidade seguinte, nos enunciados de CEP.
O Gráfico 8 sugere que realmente houve uma diferença de tom entre as unidades adjacentes, evidenciando o que Swerts (1997) denomina de descontinuidade melódica, quando ocorre um reinício da frequência fundamental (pitch reset), à medida que uma nova unidade prosódica é enunciada.
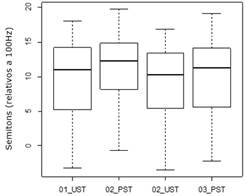
Embora o contorno continuativo interno, encontrado a partir dos pontos alvo selecionados pelo script ProsodyPro, tenha sido ascendente, os dados de f0 máxima na primeira e última sílabas tônicas das unidades prosódicas do CEP revelaram um reinício da f0 (pitch reset) a cada nova unidade prosódica, visível no Gráfico 8. Fato já constatado no português brasileiro para sentenças não numéricas (Oliveira Jr 2000), e também em outras línguas, como por exemplo, o holandês (Swerts 1997), e o sueco (Swerts et al. 1996). Entretanto, os resultados do teste estatístico ANOVA mostram que não houve diferença significativa de variação da f0 entre as unidades adjacentes de enunciação do CEP.
Tabela 5: Resultados estatísticos relativos à diferença de tom entre unidades adjacentes
| Diferença de tom | Teste ANOVA |
| 01_UST - 02_PST | F (1, 128) = 2,51, p > 0,05 |
| 02_UST - 03_PST | F (1, 128) = 0,59, p > 0,05 |
Portanto, embora seja visível o reinício da frequência fundamental entre as unidades prosódicas adjacentes, no Gráfico 8, essa diferença não se mostrou estatisticamente significativa na enunciação espontânea dos números de CEP (Tabela 5).
Tal constatação talvez seja explicada pelo fato de estarmos analisando enunciados curtos, já que sentenças mais longas apresentam maiores valores de pitch reset enquanto que em sentenças mais curtas as declinações de cada unidade prosódica permanecem bastante constantes, como constatamos na análise de variação da f0.
4. Conclusão
Observamos que a distribuição numérica padrão dos agrupamentos de código de endereçamento postal (CEP) no português brasileiro, falado em Alagoas, Bahia e Sergipe, foi representada pela forma numérica 2-3-3, mantendo uma relação direta com a forma gráfica. Esse comportamento corrobora estudos anteriores (Halford et al. 2007, Cowan 2010) que, ao abordarem a distribuição de dígitos em línguas naturais, apontam como estratégia de armazenamento uma preferência de organização subdividindo o agrupamento em unidades pequenas, com dois ou até três elementos.
De acordo com Baumann e Trouvain (2001), o agrupamento de números de identificação é peculiar em vários aspectos, pois geralmente não são tratados como uma única unidade, como o são unidades monetárias ou problemas aritméticos. Os autores identificaram que as unidades preferidas são binárias ou ternárias, inserindo às vezes, dígito único. O que também constatamos na presente pesquisa.
Os contornos entoacionais de todas as unidades prosódicas dos agrupamentos de números de CEP iniciaram com um tom médio, seguido de alternâncias entre subidas e descidas, sendo que as fronteiras prosódicas foram marcadas por um contorno ascendente ao final de cada unidade prosódica e o término do agrupamento numérico inteiro apresentou contorno descendente. Tais descrições foram confirmadas em curvas representativas do contorno entoacional normalizadas temporalmente (Xu 2013).
Ao considerarmos todo o agrupamento numérico, as representações gráficas do contorno entoacional das três unidades prosódicas se fundem de modo a apresentar uma tendência em enunciar espontaneamente um número de CEP, através da distribuição numérica 2-3-3, com um contorno entoacional padrão representado por uma curva ilustrada no Gráfico 9.

Gráfico 9: Representação gráfica e simbologia do padrão de contorno entoacional da distribuição numérica mais frequente do CEP (2-3-3)
A representação de contorno entoacional padrão de CEP demonstra que a linha de base e a linha de topo da curva declinam suavemente, assim como acontece com o padrão entoacional de frases declarativas neutras não numéricas no português brasileiro (Moraes 1998, Oliveira Jr 2000) que é caracterizado por apresentar uma f0 descendente no final do enunciado, mais precisamente na tônica final, enquanto que o tom inicial se encontra em um nível médio. A identificação de um contorno entoacional padrão, bem como a utilização de outras informações prosódicas de números nominais, são essenciais para o aprimoramento de sistemas de síntese e reconhecimento de fala.
O tom de subida no final das unidades prosódicas indica a presença de uma fronteira prosódica alta, e o tom de descida no final da última unidade prosódica é típico de encerramento de enunciado, conforme achados anteriores para o português brasileiro (Moraes 1998, 2008, Oliveira Jr 2000, Cunha 2000, Frota e Vigário 2000, Tenani 2002, Serra 2009, 2016, Cardoso et al. 2014, Silvestre 2012, Lucente 2012). Além disso, foi possível perceber que houve uma queda da curva no final do enunciado, configurando outra característica encontrada em assertivas no PB (Moraes 1998, Oliveira Jr 2000).
Nas análises acústicas referentes à característica prosódica de variação da f0 nas unidades prosódicas, constatamos que não houve diferença estatisticamente significativa entre as unidades. Provavelmente porque havia contorno continuativo (alto) nas fronteiras direitas das unidades prosódicas mediais (internas). A presença de pausas entre as unidades prosódicas também não foi significativa, tal resultado sugere que a pausa não se mostrou relevante para demarcação de unidades prosódicas na produção de enunciados numéricos de CEP.
Swerts (1997) e Oliveira Jr. (2000) afirmam que é comum haver uma queda da frequência fundamental dentro de cada unidade prosódica, fato que também constatamos em nossos dados. Embora a ação da declinação seja menor quando há subida melódica no final de unidades prosódicas internas, como acontece neste estudo, verificamos diferença significativa no declínio da f0 dentro das unidades prosódicas através do comportamento da f0 máxima na primeira sílaba tônica e na última sílaba tônica dessas unidades. Ao considerarmos o agrupamento como um todo, percebemos que esse declínio foi ainda mais significativo.
Procedemos à mensuração da diferença de tom a partir de valores de pitch range entre duas unidades adjacentes, seguindo Oliveira Jr (2000), no intuito de observar a presença de reinício da f0 (pitch reset) a cada unidade prosódica enunciada. Verificamos que, apesar de não ter apresentado diferença significativa, realmente houve uma diferença de tom entre as unidades adjacentes nos dados analisados.
Os resultados da presente investigação experimental demonstraram que os falantes do português brasileiro são conscientes da existência de uma estrutura numérica subjacente, e que essa consciência é evidenciada através do uso sistemático de vários elementos prosódicos. Ou seja, os números de CEP agrupados em estruturas fixas apresentam uma estrutura razoavelmente previsível, que é sistematicamente sinalizada por diversas pistas prosódicas, sobretudo as de natureza entoacional.
Nossos achados confirmam a hipótese de que os enunciados numéricos apresentam características prosódicas semelhantes às apontadas em estudos prévios para sentenças declarativas neutras não numéricas no português brasileiro. Além disso, os resultados do teste Kappa de concordância ratificam outra hipótese, qual seja, a de que o falante possui intuitivamente a capacidade de perceber o local das fronteiras prosódicas, assim como já foi comprovado com sentenças não numéricas em investigações anteriores (Swerts 1997, Mo et al. 2008, Oliveira Jr et al. 2012).
Apesar dessa pesquisa objetivar reduzir uma lacuna na literatura reservada à descrição prosódica de números nominais no português brasileiro, entendemos que ainda há muito a ser feito, sobretudo no que diz respeito à aplicabilidade dos dados que estão disponibilizados para futuras investigações.

