











 texto en
texto en  Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo

 Permalink
Permalink
La Teoría de la Respuesta al Ítem (TRI)
Es consensuado actualmente entre los psicometristas que la teoría clásica de los tests (TCT) tiene ciertas limitaciones (Attorresi, Lozzia, Abal, Galibert, & Aguerri, 2009). Entre ellas: (a) todas las medidas que se obtienen (e.g. el Alpha de Cronbach) dependen de la muestra particular de individuos que respondieron al instrumento, (b) instrumentos con índices de dificultad y discriminación diferentes generan resultados diversos en los mismos individuos, y (c) si el mismo constructo es medido por dos o más test diferentes, los resultados no son medidos en la misma escala. Por otra parte, la relación lineal ítems-constructo que supone la TCT podría no ser demasiado realista en muchos casos.
Se ha afirmado frecuentemente (e.g. Paek & Cole, 2019) que la teoría de la respuesta al ítem (TRI) resuelve muchas de las limitaciones de la TCT, aunque al costo de una mayor demanda matemática y computacional, el requerimiento de una muestra grande y supuestos más exigentes. Sin embargo, con los avances en capacidad computacional y programación, los expertos de muchos campos accedieron a los beneficios de aplicar la TRI.
La TRI es un conjunto de modelos orientados a explicar la relación entre las respuestas observadas a un ítem -que forme parte de una escala- y un constructo subyacente (Cappelleri, Lundy, & Hays, 2014). Para ello, los modelos de la TRI utilizan funciones matemáticas no lineales, frecuentemente la función logística, que describen la asociación entre el nivel del participante en un rasgo latente θ y la probabilidad de seleccionar una determinada respuesta -o categoría de respuesta- a un ítem. En el ejemplo que se brinda en este estudio, el rasgo latente θ es el nivel de soledad.
La primera cuestión a tener en cuenta para seleccionar un modelo de la TRI es la categorización de las opciones de respuesta de los ítems. Si esta categorización resulta en una dicotomía, los modelos más utilizados son los Modelos Logísticos de Uno (ML1P), Dos (ML2P) o Tres Parámetros (ML3P). Si se trata de tres o más categorías de respuesta, serán apropiados los modelos de la TRI para ítems con respuesta politómica. Si la respuesta politómica no es ordenada, se utiliza el Modelo de Respuesta Nominal (Bock, 1997). Los modelos más utilizados en la actualidad para respuesta politómica ordenada son: el Modelo de Respuesta Graduada (MRG; Samejima, 1969; 2016) y su versión restringida (Reduced GR Model, MRGR;Toland, 2013), el Modelo Generalizado de Crédito Parcial (MGCP; Muraki, 1992) y el Modelo de Crédito Parcial (MCP; Masters, 1982, 2016). Aunque se ha planteado la elección entre los modelos politómicos de la TRI como una cuestión de preferencia del investigador (e.g. Edelen & Reeve, 2007), actualmente existen métodos objetivos para comparar el ajuste relativo entre modelos con respecto a un determinado conjunto de datos (e.g. DeAyala, 2009; Toland, 2013) para poder determinar cuál es en cada caso el más adecuado.
Además, una cuestión muy importante para ofrecer garantías de validez de la escala es el análisis del funcionamiento diferencial del ítem (differential item functioning, DIF). La existencia de ítems con DIF atenta contra la unidimensionalidad cuando se pretende medir un único rasgo y pone en riesgo a la validez. Usualmente los estudios de DIF comparan entre dos grupos, denominados De Referencia y Focal. Si un ítem tiene DIF, en este caso implica que iguales puntuaciones en el ítem están representando diferentes niveles de soledad entre los dos grupos, lo que definitivamente no es una característica deseable en una técnica psicométrica.
La Escala de Soledad de Buenos Aires
El propósito fundamental de este artículo es exponer los pasos necesarios para conducir, interpretar y presentar los resultados de la modelización con TRI en un formato accesible. Los pasos generales para realizar un análisis con TRI incluyen: (a) clarificar el objetivo del estudio, (b) considerar modelos relevantes, (c) testear los supuestos de los modelos y comparar su ajuste relativo y (d) aplicar el modelo seleccionado e interpretar los resultados. Para ejemplificar este análisis con TRI en forma didáctica, se ha elegido la Escala de Soledad de Buenos Aires ((ESBA); Auné, Abal & Attorresi, 2019) como técnica psicométrica a modelizar.
Se trata de un nuevo instrumento para evaluar la autopercepción de la soledad. Es un test breve, unidimensional, conformado por siete ítems de respuesta politómica, los cuales fueron redactados en base a entrevistas grupales a población general adulta y de la tercera edad residentes en el Área Metropolitana de Buenos Aires (AMBA). Aunque existía una escala adaptada al país para medir la soledad, se realizó un estudio de la misma que evidenció que las respuestas a los ítems se veían influenciadas por la dirección de respuesta (Auné, Abal & Attorresi, 2020).
Inicialmente se obtuvieron evidencias de validez de contenido mediante el acuerdo interjueces utilizando el índice V de Aiken (Aiken, 1980, 1985) y se realizó un estudio piloto. Se realizó un Análisis Factorial Exploratorio, descartando los ítems que poseyeran uno o más de los siguientes criterios: a) asimetría y curtosis exageradas, b) elevados residuos estandarizados (> 2.58, criterio de Hair, Anderson, Tatham, & Black, 1999) y c) carga factorial menor a .40. Una vez depurados los ítems, se obtuvieron evidencias de validez convergente con la versión argentina de la UCLA (Sacchi & Richaud de Minzi, 1997) y con la autopercepción del nivel de soledad, así como evidencias de validez discriminante con respecto a la deseabilidad social. La consistencia interna fue muy adecuada (alfa de Cronbach = .80, alfa ordinal = .87). Se realizaron, además, estudios de funcionamiento diferencial del ítem con respecto al género, hallándose que los ítems se hallaban libres de funcionamiento diferencial en este aspecto.
Objetivos
El objetivo general de este trabajo es ejemplificar la modelización de una escala psicométrica de respuesta politómica con TRI mediante el análisis de los ítems que componen la ESBA.
Los objetivos específicos son los siguientes:
a- Comprobar los supuestos de los modelos de la TRI de unidimensionalidad e independencia local.
b.- Comparar entre los modelos MRG, MRGR, MGCP y MCP y determinar cuál es el más adecuado para calibrar las respuestas a los ítems que componen la ESBA.
c.- Explorar la existencia de Funcionamiento Diferencial del Ítem según el estado civil de los participantes utilizando el modelo de la TRI seleccionado.
d.- Calibrar los ítems de la ESBA con los parámetros del modelo seleccionado.
e.- Analizar para qué niveles de soledad es la ESBA resulta más precisa.
Método
Participantes
Se recolectó de una muestra no probabilística e incidental de 509 participantes. Los mismos fueron en un 53% mujeres y residían en el AMBA. Su promedio de edad fue de 44.3 (DE = 13); 47.2% manifestó que se encontraba casado o en unión de hecho, 25% soltero/a, 15.3% divorciado/a, 4.7% viudo/a, mientras que 7.9% seleccionó la opción “otro”.
Procedimiento
Se recolectaron los datos mediante un diseño muestral no probabilístico por accesibilidad. El protocolo fue administrado en formato de encuesta online, donde se incluía un consentimiento informado anónimo. Además, se aclaraba que el uso era exclusivamente para fines de investigación y la participación enteramente voluntaria, pudiendo cesar en cualquier momento.
Instrumentos
Cuestionario Sociodemográfico. Consta de una serie de preguntas realizadas ad hoc para la presente investigación que indagaron las variables de género, edad, estado civil, nacionalidad y lugar de residencia.
Escala de Soledad de Buenos Aires (ESBA); Auné, et al., 2019). Se trata de un instrumento de siete ítems, donde la modalidad de respuesta se especifica mediante una escala Likert de cuatro opciones (1 = Nada de Acuerdo, 2 = Poco de Acuerdo, 3 = Algo de Acuerdo, 4 = Totalmente de Acuerdo).
Cumplimiento de los Supuestos de los Modelos de la TRI
La verificación del supuesto de unidimensionalidad requerido por los modelos MRG, MRGR, MGCP y MCP a comparar se realizó mediante la implementación óptima del análisis paralelo (Timmerman, & Lorenzo-Seva, 2011) y el porcentaje de varianza explicada por el primer factor. Ambos índices se obtienen mediante un Análisis Factorial Exploratorio (Ferrando & Lorenzo-Seva, 2017a).
Además del supuesto de unidimensionalidad, los modelos MRG, MRGR, MGCP y MCP también asumen que, dado un nivel fijo de θ, las respuestas a los ítems son independientes entre sí. El índice X2 LD (Chen & Thissen, 1997) se calcula para cada par de ítems e indica el no cumplimiento del supuesto cuando es mayor que 10.
Comparación entre Modelos de la TRI
Para comparar el ajuste relativo de los modelos MRG, MRGR, MGCP y MCP se utilizaron múltiples métodos, tal como lo describen De Ayala (2009) y Toland (2013). Por una parte, se implementó el Test de la Razón de Verosimilitudes (Likelihood Ratio Test; LRT) que compara dos modelos anidados, complementado con el estadístico R Δ 2 (Haberman, 1978). En este caso el MRGR es una restricción del MRG y el MCP del MGCP. El LRT informa acerca de si la complejidad del modelo completo, sin restricciones en el parámetro a, es necesaria para mejorar el ajuste del modelo. Adopta una distribución χ2, donde un estadístico χ 𝛥 2 no significativo implica que la complejidad adicional del modelo no restringido es innecesaria para mejorar el ajuste de los datos. El estadístico R 𝛥 2 mide en qué porcentaje el modelo completo aumenta la explicación de las respuestas a los ítems con respecto al modelo reducido. El R 𝛥 2 se calcula como: (valor del logaritmo de la verosimilitud del modelo restringido - valor del logaritmo de la verosimilitud del modelo completo) / valor del logaritmo de la verosimilitud del modelo restringido (Toland, 2013).
Por otra parte, se calcularon el Criterio de Información de Akaike (Akaike Information Criterion, AIC) y el Criterio de Información Bayesiano (Bayesian Information Criterion, BIC) para cada uno de los modelos, donde valores más pequeños de AIC y BIC indican mejor ajuste relativo. Por último, se observó el ajuste global y la existencia de desajuste de ítems de cada uno de los modelos. El ajuste global se calculó con el estadístico M2 (Maydeu Olivares & Joe, 2005, 2006) y el índice RMSEA asociado, considerándose que el modelo ajusta si RMSEA ≤ .05. Valores más pequeños del estadístico M2 señalan un mejor ajuste. Para determinar si cada ítem es explicado por un modelo se calculó el índice S-χ2 (Orlando & Thissen, 2000, 2003). Si el valor p asociado al S-χ2 es mayor que .01 indica ajuste (Toland, 2013).
Análisis del Funcionamiento Diferencial del Ítem
Se exploró la existencia de DIF por estado civil, dividiendo a la muestra entre quienes estaban casados o en unión de hecho y los participantes que seleccionaron otros estados civiles. Se realizó este análisis mediante la serie de pasos detallados por Woods (2009). Como primer paso, cada uno de los reactivos de la ESBA se verificó con el test de Wald modificado (Cai, 2012; Cai, Thissen, & du Toit, 2011; Langer, 2008) considerando el resto como anclaje. Posteriormente, se realizó un segundo paso, donde se testeó a un ítem con potencial DIF con anclaje en las respuestas al ítem más certeramente libre de DIF, evitando así la contaminación.
Evidencias en el Marco de la TRI
Se obtuvieron evidencias de confiabilidad en el marco de la TRI, mediante la Función de Información de los Ítems (FII) y la Función de Información del Test (FIT). La FII indica la precisión de determinado ítem en la medición de cada nivel de θ. La sumatoria de las FII conforma la FIT, que informa la confiabilidad de la escala según el nivel en el rasgo θ.
Softwares Utilizados
Los índices de unidimensionalidad se obtuvieron con el programa FACTOR versión 10.5 (Ferrando & Lorenzo-Seva, 2017b). Los análisis de independencia local, DIF y modelización con TRI se implementaron mediante el programa IRTPRO 4.2 (Cai et. al, 2011).
Resultados
Cumplimiento de los Supuestos de los Modelos de la TRI
La implementación óptima del análisis paralelo indicó que la cantidad sugerida de factores es uno, mientras que el porcentaje de varianza explicada por el primer factor fue de 57.48%. Por lo tanto, los datos pueden considerarse esencialmente unidimensionales. En las salidas de cada uno de los modelos MRG, MRGR, MGCP y MCP el índice X2 LD resultó menor que 10 para cada par de ítems. Por lo tanto, para los cuatro modelos se pueden dar por satisfechos los dos supuestos, unidimensionalidad e independencia local.
Comparación entre Modelos de la TRI
Los índices de ajuste para MRG, MRGR, MGCP y MCP se pueden observar en la Tabla 1. Aunque todos los modelos ajustaron globalmente, el MRG obtuvo valores más pequeños en estadístico M2, logaritmo de la verosimilitud, AIC y BIC. El LRT entre el MRG y el MRGR indicó que la complejidad adicional del modelo completo es necesaria para mejorar el ajuste a los datos ya que χ 𝛥 2 (6) = 7108.19 - 7011.88 = 96.31, p = 7.07x10-19. El cambio relativo entre estos modelos fue de R 𝛥 2 = .0135, es decir que el MRG mejora la explicación de los datos por sobre el MRGR en un 1.35%. Muy similares resultados se obtienen en la comparación del MGCP y el MCP. El LRT entre el MGCP y el MCP resultó de χ 𝛥 2 (6) = 5939.43-5866.85 = 72.58, p = 1.21x10-13. En este caso el R 𝛥 2 = .0122, señalando una mejora en el modelo completo de 1.22%. Para todos los modelos, ningún ítem desajustó ya que el p asociado al S-χ2 fue mayor que .01, para todos los reactivos.
Dado que un modelo con parámetro a libre es necesario para mejorar tanto el ajuste como la explicación de estos datos y que el MRG es el modelo con mejor ajuste relativo, se lo selecciona para la modelización con TRI de las respuestas a los ítems de la escala.

Modelización de la ESBA con el MRG
El MRG fue, de los cuatro modelos, el que resultó más adecuado. Supone que un único θ -en este caso el nivel de soledad- explica no linealmente las respuestas a los ítems. Para cada uno de los reactivos fueron calculados un parámetro de inclinación a y tres parámetros de umbral de categoría b m , dado que las opciones de respuesta son cuatro. El parámetro a informa el grado en que las categorías de respuesta distinguen entre los niveles de θ. Además, se lo ha comparado con las cargas factoriales, en tanto refleja la magnitud de la relación de cada ítem de la escala con el rasgo latente θ. Cada parámetro b m informa el nivel de soledad -θ- que se necesita para tener igual probabilidad (.50) de seleccionar la categoría de respuesta m o superior con respecto a las categorías inferiores. Así, las opciones de respuesta de los ítems son separadas en una serie de dicotomías en cada una de las cuales se aplica el ML2P. Las CCCRI representan la probabilidad de seleccionar cada categoría de respuesta según el nivel de θ.
Análisis del Funcionamiento Diferencial de los Ítems
Los resultados de explorar la presencia de DIF utilizando para cada ítem al resto como anclaje se encuentran en la Tabla 2. El ítem 5 - Estoy completamente fuera de todo grupo social - fue señalado por los análisis como candidato a tener DIF no uniforme por género, aunque el valor p estaba muy cercano al límite de .05. Se implementó entonces el segundo paso del método de Woods (2009), tomando al ítem 2 como anclaje entre los dos grupos. Este ítem tiene el menor valor de χ2 Total por lo cual se asume que es el más libre de DIF. El resultado estadísticamente no significativo de este segundo paso indicó que el ítem 5 no exhibe DIF (𝜒2 a = 2.6, gl = 1, p = .1048). Por lo tanto, la totalidad de los ítems de la escala se pueden considerar libres de DIF según el estado civil.

Calibración de los Ítems con el MRG
Los resultados de la aplicación del MRG a la escala indicaron que el modelo ajustó tanto globalmente (M2 = 391.86; gl = 182; p = 0.0001; RMSEA = 0.05) como al nivel de los ítems (p asociado al S-χ2 > .01). Se estimaron 28 parámetros, cuyos valores se exponen en la Tabla 3.
Los parámetros de umbral de los ítems de encuentran repartidos en un espectro relativamente amplio del rasgo latente, desde -1.43 (b1 ítem 3) a 3.15 (b3 ítem 7). Se puede observar una relativa heterogeneidad de los b1, mientras que los b2 se encuentran en niveles medios o altos del rasgo, y los b3 en niveles aún más altos.
En cuando a los parámetros de discriminación a, los mismos tomaron valores desde 1.11 a 3.01. Esto indica que las categorías de respuesta son potentes para distinguir entre participantes con diferentes niveles de soledad, siendo su capacidad de discriminación moderada en el caso de los ítems 3 y 7, alta en el caso del ítem 6 y muy alta para los ítems 1, 2, 4 y 5 (Baker & Kim, 2017).
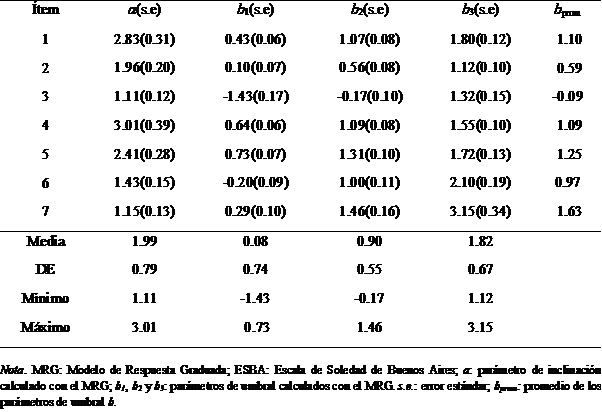
En la Figura 1 se muestran las CCCRI del ítem 3, aquél con menor parámetro a. Como se puede observar, las CCCRI correspondientes a las categorías de respuesta centrales muestran una forma achatada. Para este ítem si bien todas las opciones de respuesta son máximamente probables en algún nivel del rasgo, la categoría Poco de Acuerdo lo es en un rango acotado. Dado el parámetro b promedio de -0.09 se lo puede considerar un ítem de dificultad media. Es suficiente un nivel muy bajo en el rasgo para seleccionar la categoría Poco de Acuerdo o una superior, un nivel medio para seleccionar las categorías Algo o de Acuerdo o Totalmente de Acuerdo por sobre las dos anteriores y es necesario un nivel muy alto en el rasgo para seleccionar la categoría superior Totalmente de Acuerdo. Por tanto, es factible afirmar que las categorías de respuesta se comportan de una manera esperable.
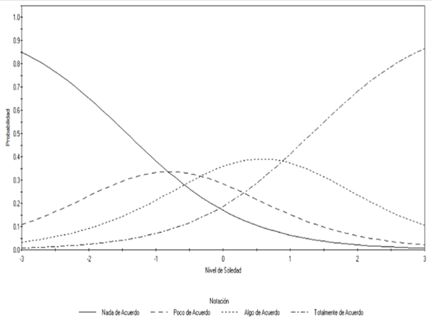
En la Figura 2 se muestran las CCCRI del ítem 4, aquél con parámetro a más grande. En este caso, las CCCRI correspondientes a las categorías de respuesta extremas muestran una forma elevada. Aunque todas las opciones de respuesta son máximamente probables en algún nivel del rasgo, las opciones intermedias lo son en un lapso muy pequeño. Dado el parámetro b promedio de 1.09 se lo puede considerar un ítem de dificultad alta. Aunque las categorías de respuesta se comportan de una manera esperable, este ítem sería apto para integrar una prueba dicotómica.
Evidencias de Confiabilidad
En la Tabla 4 se observan valores puntuales de las FIIs y FIT para determinados niveles de soledad distribuidos a lo largo del continuo del rasgo. La mayoría de los ítems, así como el test completo, evidencian brindar un mayor nivel de información para niveles medios y altos de soledad, donde a su vez disminuye el error estándar (standard error, s.e.). Los ítems poseen cierta paridad en el nivel de información máxima que brindan.
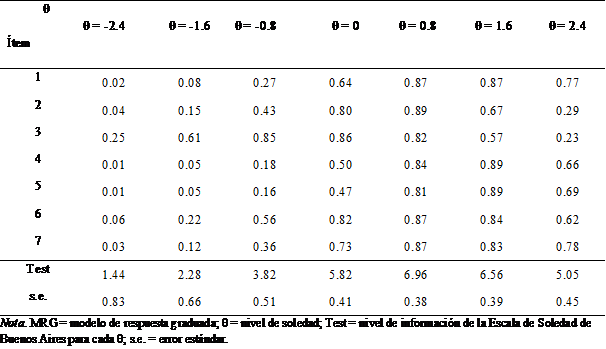
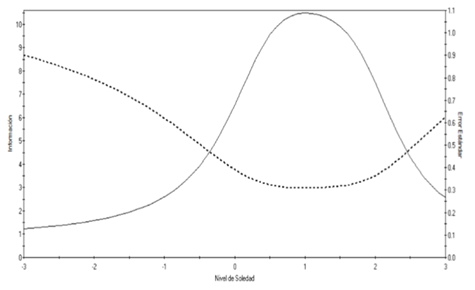
La Figura 3 muestra la FIT. Esta alcanzó para el MRG su valor máximo de 6.9983 en θ = 1.00 con un valor mínimo del s.e. en ese punto de 0.378. El nivel de información fue mayor en los niveles medios y altos del rasgo, decreciendo considerablemente en los niveles bajos del rasgo, así como aquellos altos en extremo.
Discusión
Este artículo ha mostrado cómo llevar a cabo un análisis con TRI en sus diferentes aspectos, proveyendo detalles que permiten la replicabilidad a través de la descripción detallada de los pasos necesarios para realizar este tipo de modelización. Es necesario mencionar, para el investigador que desee introducirse en el análisis con TRI, que el programa IRTPRO cuenta con una versión estudiantil, de descarga gratuita, la cual puede ser utilizada para un realizar un acercamiento inicial al análisis con TRI.
En cuanto a los resultados obtenidos, el análisis de la ESBA con el MRG evidenció que la escala tiene un nivel más elevado de precisión en niveles medios y altos del rasgo. El error de medición crece sustancialmente hacia niveles bajos de soledad. La capacidad discriminativa, así como el nivel de información alcanzado tuvieron valores adecuados para la totalidad de los ítems que componen la ESBA. Los nuevos ítems que se incorporen a la ESBA deberían requerir un nivel bajo de soledad para que la escala pueda medir con similar precisión a los distintos niveles del rasgo.
En cuanto al análisis de la adecuación de la cantidad de opciones de respuesta, los valores relativamente alejados de los parámetros b m indican su adecuación. Además, resultados empíricos y en base a simulación indican que un diseño de respuesta con cuatro opciones favorece el equilibrio entre la precisión de la medida y el grado de ajuste del modelo de la TRI (e.g. Abal, Auné, Lozzia & Attorresi, 2017; Lozano, García-Cueto & Muñiz, 2008).
Con respecto a un análisis detallado de los reactivos, los ítems 1, 4 y 5 fueron los que brindaron los niveles más altos de información. Además, el parámetro de inclinación a de estos ítems es muy alto y las distancias entre los parámetros b m son amplias, lo que indica que las categorías de respuesta resultan eficaces para discriminar entre participantes con diferentes niveles de soledad. Los restantes ítems, si bien tienen una calidad psicométrica aceptable, son menos informativos que los anteriores.
El análisis del DIF tuvo como resultado la conclusión de que la Escala de Soledad de Buenos Aires se encuentra libre de DIF según Estado Civil, además de por género como ya se había probado en su construcción (Auné et al., 2019). Esto muestra la importancia de los estudios del DIF, tan poco frecuentes sobre todo en el medio latinoamericano. La existencia de ítems con DIF resta validez a la interpretación de los puntajes de la escala, de manera que es necesario testear todos los ítems que se incorporen a la escala en este sentido. Además del DIF estado civil y por género, se puede analizar con respecto a variables sociodemográficas e incluso psicológicas obteniendo así resultados de mucho interés. En futuros estudios se analizará el DIF por edad y por nivel del participante en la Escala de Conducta Empática (Auné et al., 2017a) y en la adaptación argentina de la Escala de Felicidad de Lima (Auné, Abal, & Attorresi, 2017b).
Otra cuestión para destacar es la relevancia de la comparación entre modelos de la TRI. Se pudo observar que no todos los modelos de la TRI ajustaron en el mismo grado a los datos obtenidos empíricamente, las respuestas a la Escala de Soledad de Buenos Aires de esta muestra en particular. Los modelos aplican distintas formas de segmentación del ítem politómico y utilizan diferentes procedimientos para el cálculo de las probabilidades de respuesta de las categorías. Para los tests de comportamiento típico, los resultados de este estudio concuerdan con otros donde el MRG ajustó mejor que los restantes modelos comparados (e.g. Abal, 2013; Asún & Zuñiga, 2008).

